Ottantacinquemila dipendenti di Meta compaiono in una classifica interna dedicata al tokenmaxxing. Si chiama Claudeonomics, l’hanno costruita loro stessi incrociando i dati di utilizzo aziendale, e misura una cosa sola: quanti token ciascuno consuma lavorando con l’AI. In cima ci sono i “Token Legend”, vince chi ne brucia di più. A fine aprile Business Insider ha raccontato la lista, a fine maggio Amazon ha spento la sua versione interna dello stesso gioco, e a giugno Fortune titolava che il tokenmaxxing era già finito.
Finito nella forma che fa notizia, forse. Nella forma che sposta budget vero dalle assunzioni al motore agentico, il tokenmaxxing è appena cominciato, e le due cose vengono continuamente confuse.
Amazon ha spento la classifica interna sui token
La dinamica descritta da chi l’ha vissuta è semplice. Un dashboard aziendale mette in fila i dipendenti per numero di token consumati, il numero diventa visibile ai manager, e da lì in poi la classifica smette di misurare qualcosa e comincia a determinarlo. È il meccanismo che gli economisti chiamano legge di Goodhart: una misura, appena diventa un obiettivo dichiarato, smette di essere una buona misura. Al Financial Times alcuni dipendenti Amazon hanno raccontato di aver fatto girare agenti su compiti inutili solo per restare in classifica, mentre Uber, secondo Fortune, ha esaurito l’intero budget AI del 2026 in quattro mesi.
Il paradosso è che nessuno, in questa versione del fenomeno, sta ridisegnando un solo processo. Si sta solo alzando un contatore. Ridisegnare i flussi di lavoro attorno all’AI è lavoro lento, spendere token per apparire “AI-native” è immediato, e la seconda cosa continua a travestirsi da prova della prima.
Il bilancio AI di Uber esaurito in quattro mesi
Quello che rende interessante il 2026, però, è che nello stesso periodo circola un’idea quasi opposta, con lo stesso nome. Y Combinator la spiega ai suoi fondatori così: tokenmaxx, non headcountmaxx. Diana Hu, partner del fondo, lo dice senza troppi giri: una persona con gli strumenti giusti oggi può valere quello che prima valeva un intero team di ingegneria, e un budget API “scomodamente alto” è spesso più economico di un organico gonfiato.
Qui il token non è un trofeo da esibire su una classifica interna, è una voce di bilancio che sostituisce uno stipendio. Una startup che nasce nel 2026 non deve disimparare trent’anni di processi legacy per diventare AI-native, li costruisce così fin dal primo giorno: meno persone, più agenti, decisioni che si prendono dentro un flusso continuo invece che in una riunione settimanale.
Due aziende possono dichiararsi entrambe “tokenmaxxing” e fare l’esatto contrario: una infila numeri in un dashboard per sembrare avanti, l’altra riscrive l’organigramma attorno a quei numeri.
Cosa distingue un token che produce conoscenza da uno sprecato

Il test operativo che circola tra chi studia il tokenmaxxing è disarmante nella sua semplicità: quando il volume di token sale, cosa cambia nel lavoro che viene effettivamente accettato? Se la risposta è “niente”, si sta guardando la versione di vanità. Se la risposta è “un ciclo di revisione in meno, una decisione presa prima, un cliente servito senza aspettare”, si è dentro qualcosa che vale la pena misurare.
Un sistema che moltiplica le interazioni con l’AI senza lasciare che quelle interazioni si accumulino in qualcosa di riusabile genera un debito. Non lo vedi nella fattura del mese, lo vedi tre mesi dopo, quando ogni nuovo agente riparte da zero perché nessuno ha organizzato ciò che il primo aveva già imparato. Il vantaggio, in questo genere di sistemi, smette di stare nel modello e finisce nella memoria che un’azienda accumula, e lo stesso principio vale per il conto dei token: quel che resta dopo la spesa pesa più del numero speso.
Il ciclo che rende utile il tokenmaxxing
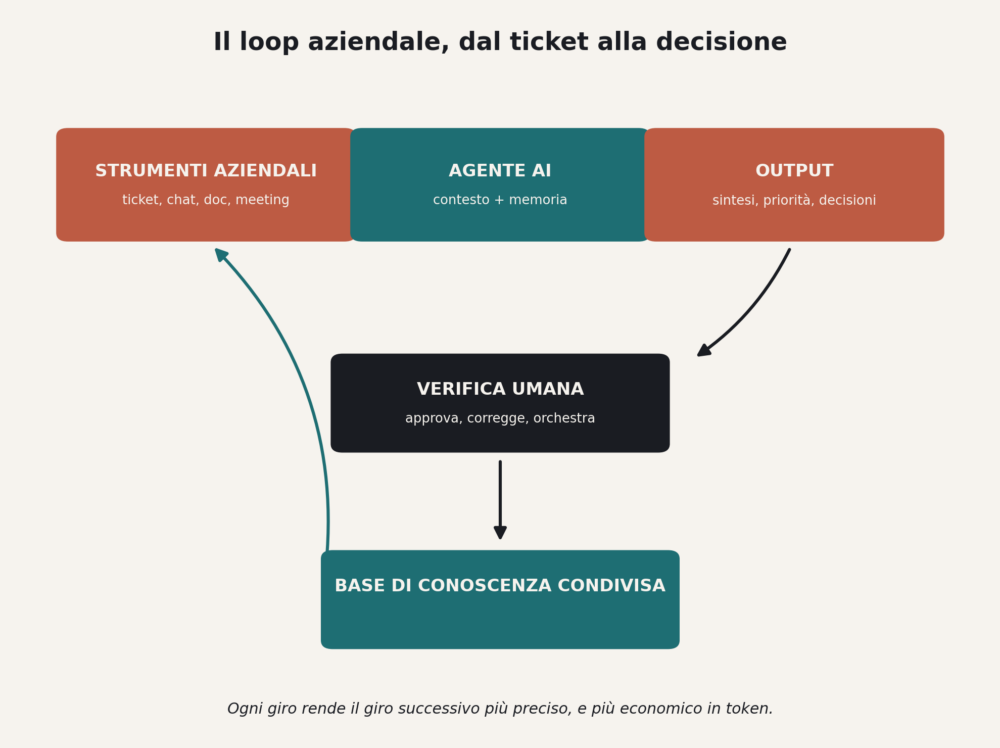
L’azienda che tokenmaxxa in modo utile non brucia token in sessioni isolate, li fa girare in un ciclo che si autoalimenta. Un ticket di supporto genera una sintesi, la sintesi aggiorna la base di conoscenza condivisa, la base di conoscenza informa il prossimo agente che risponde a un cliente simile, e ogni giro rende il giro successivo più preciso e più economico. Satya Nadella lo scorso mese ha messo lo stesso meccanismo al centro della sua visione d’impresa, chiamandolo learning loop, e il punto che aggiungo io è che il ciclo regge solo se qualcuno possiede l’infrastruttura che lo fa girare, non solo il modello che lo alimenta.
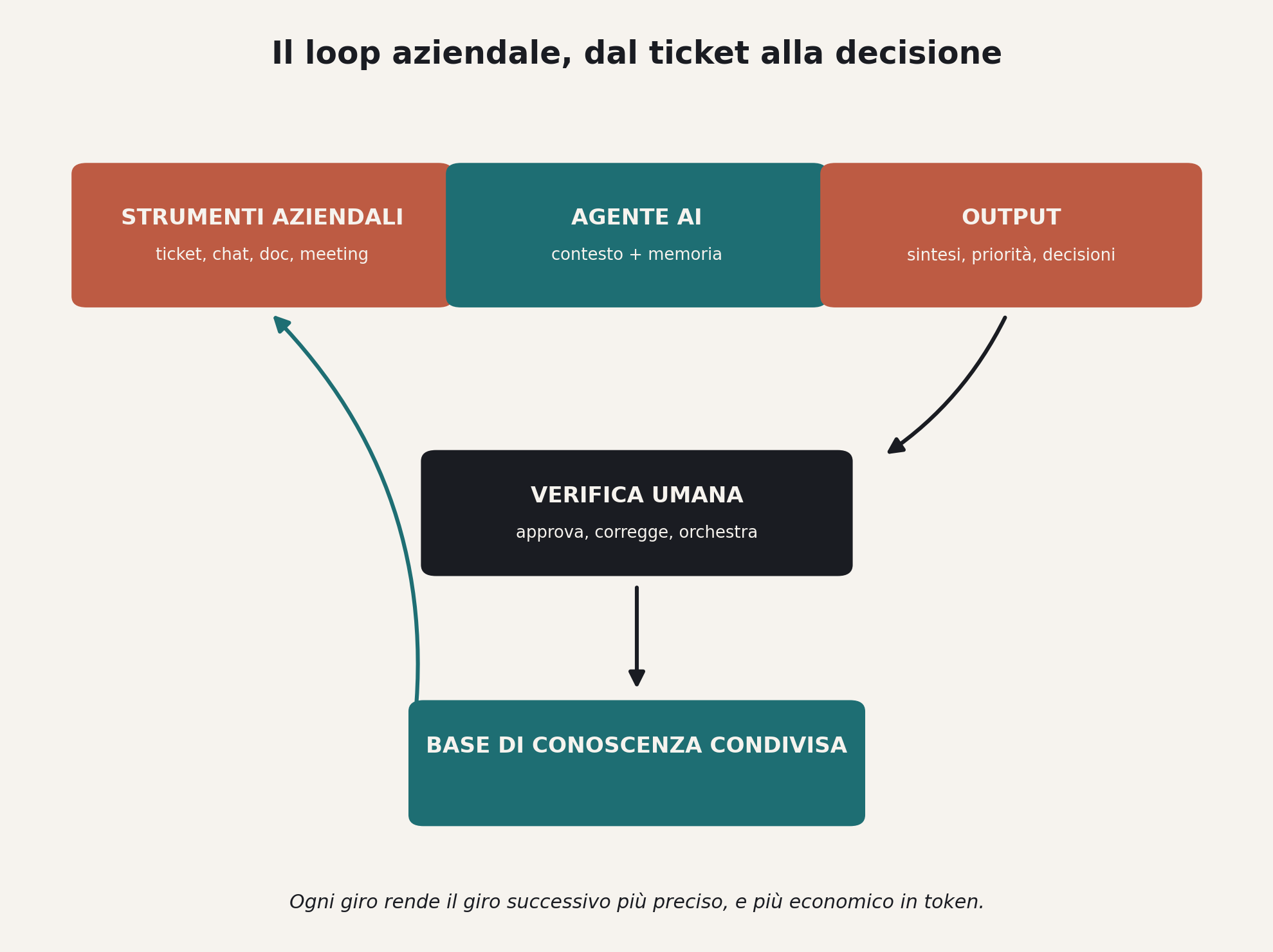
Non conta quanto token bruci ma cosa resta dopo
Le aziende nate trent’anni fa restano indietro non perché usino meno AI, ma perché il loro organigramma è stato disegnato prima che esistesse un’alternativa al mettere una persona su ogni compito. Cambiarlo ora significa smontare processi che hanno funzionato per decenni, ed è un lavoro che nessun dashboard di token può velocizzare. Le aziende che nascono oggi non hanno questo problema, e la differenza tra chi vince e chi perde questa fase si vede meno nella fattura di Anthropic o OpenAI e più in quante decisioni, alla fine del trimestre, vengono ancora prese da un umano che rilegge tutto da capo.
Il ruolo umano che resta, in questo schema, è quello descritto anche in un pezzo recente su chi oggi gestisce insieme persone e agenti: meno produzione diretta, più verifica, correzione, approvazione finale. Un lavoro che a differenza dei token non si può comprare a peso.
Chi guarda la classifica dei token e pensa di aver capito qualcosa dell’azienda del 2026 sta guardando la metrica sbagliata. La domanda utile non è quanti token, ma quanti di quei token tornano indietro sotto forma di conoscenza che il prossimo agente non deve reinventare.
Fonti: Fortune, The Pragmatic Engineer, Business Insider / Y Combinator.