Harness engineering: runtime, contesto, permessi
Il modello non è quasi mai il problema. Adnan Masood, in un’analisi dell’aprile 2026 sul control plane degli agenti, riporta che il 65% dei fallimenti dei progetti AI in azienda non nasce da carenze di ragionamento del modello, ma da difetti dell’infrastruttura che gli sta intorno, dal contesto che va alla deriva agli schemi disallineati, fino allo stato che degrada nel tempo senza che nessuno se ne accorga. Lo stesso numero gira in più rassegne di settore, e dice una cosa scomoda per chi compra licenze guardando solo i benchmark. La parte che fa fallire i progetti sta altrove, in un livello, l’harness engineering, che fino a diciotto mesi fa nessuno chiamava per nome.
Adesso un nome ce l’ha. Si chiama harness engineering, ed è diventato il mestiere che separa una demo che impressiona in riunione da un agente che regge tre mesi in produzione senza che qualcuno debba riavviarlo a mano ogni venerdì.
Harness engineering, cosa c’è davvero intorno al modello
L’harness è l’infrastruttura di runtime che avvolge il loop di ragionamento di un LLM. Salesforce lo descrive bene con un’immagine edilizia: il framework, LangChain o un agent builder qualsiasi, è il progetto dell’edificio, l’harness è il cantiere dove l’agente lavora davvero. Un paper su arXiv di marzo 2026 sull’architettura degli agenti da terminale lo definisce come il livello che coordina, a runtime, la spedizione degli strumenti, la gestione del contesto, l’applicazione delle regole di sicurezza e la persistenza dello stato fra un turno e l’altro.
Tradotto per chi deve decidere: il modello è il motore, l’harness è tutto il resto dell’auto. Senza, hai un blocco di potenza che gira a vuoto.
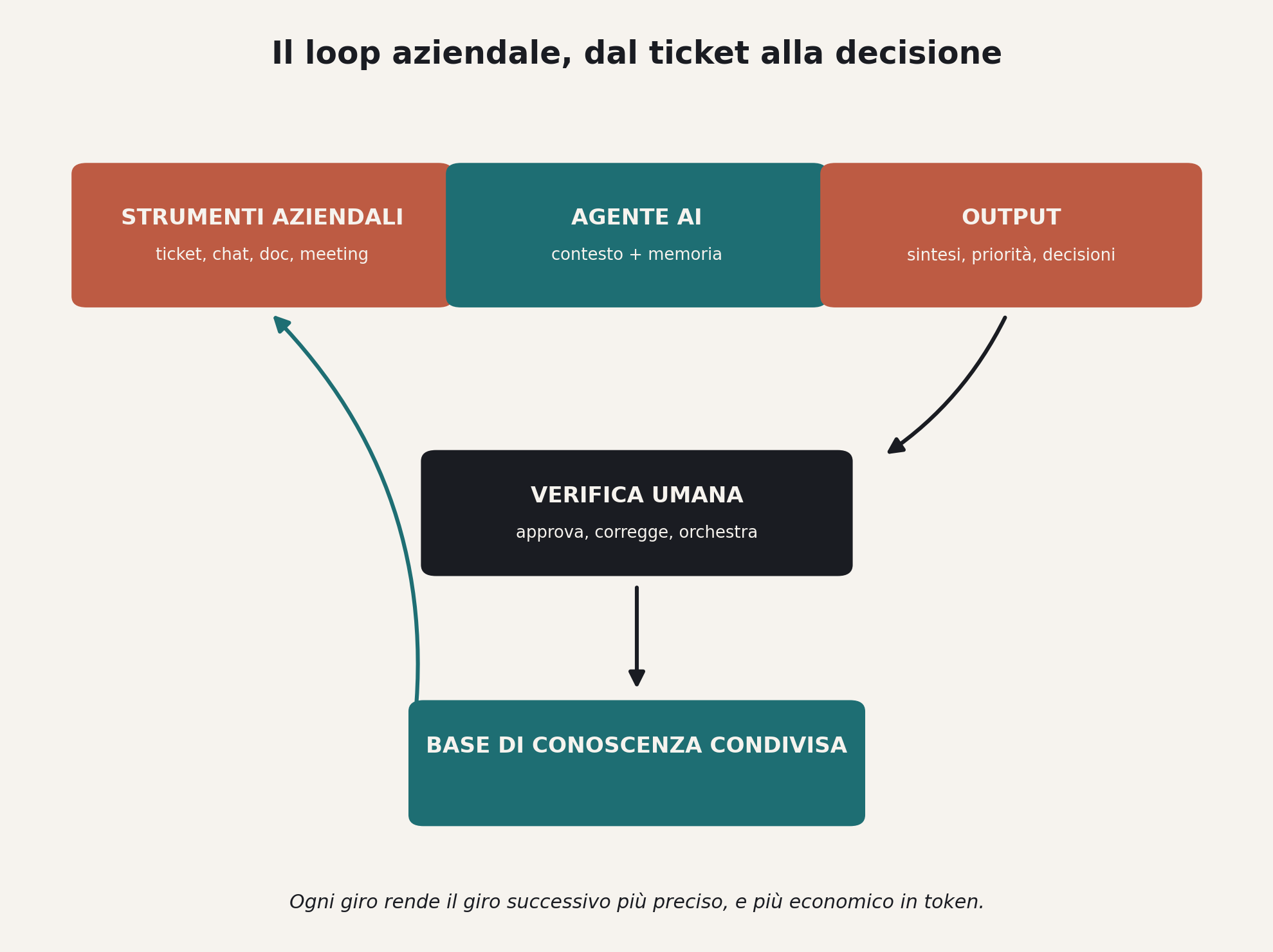
Dentro questo livello vivono sei o sette sottosistemi che lavorano insieme. L’assemblaggio del contesto, che decide cosa entra nella finestra del modello a ogni passo. I contratti degli strumenti, gli schemi che il modello deve rispettare quando chiede un’azione. La memoria, che tiene insieme un compito lungo. L’osservabilità, che permette di capire cosa è successo quando qualcosa va storto. Il recupero degli errori e l’orchestrazione, che governano la danza tra modello, strumenti e dati. Ognuno di questi è un punto dove un prototipo elegante diventa fragile.
System design per un runtime che hallucina
C’è un’obiezione che chi ha background da systems engineer fa appena sente “harness engineering”: questo lo facciamo da decenni. Loop che persistono lo stato tra una chiamata e l’altra, validazione degli input prima dell’esecuzione, retry on failure, log per l’audit. È esattamente quello che scrivi quando avvolgi un’API esterna e pensi “forse dovrei gestire il timeout”.
Akshay Kokane, in un’analisi che gira molto tra chi costruisce sistemi agentici, mette la questione in modo diretto: l’harness engineering è al 90% system design che conosci già, applicato a un substrato nuovo. Il 10% rimanente è genuinamente diverso, perché il tuo sistema ora ha al centro un componente non deterministico che può hallucinar una tool call, restituire una risposta semanticamente sbagliata o perdere il filo dell’obiettivo dopo quaranta turni di conversazione.
La differenza concreta sta in un solo punto: con un’API tradizionale validi il formato dell’output, con un agente devi validare l’intento. La pipeline di permessi di Claude Code non controlla solo se una tool call è sintatticamente valida, controlla se il modello è autorizzato a volere quello che vuole. Il vecchio stack retry-and-log non basta più perché il problema non si trova nella risposta, si trova nella richiesta, prima che qualcosa venga eseguito.
Questo spiega anche perché il nome è arrivato adesso, e perché conviene tenerlo anche se sa di marketing. Chi entra nell’AI engineering senza anni di systems engineering alle spalle ha bisogno di un vocabolario per afferrare questi pattern. Chi conia quel vocabolario si prende conferenze, SEO e mindshare, certo, ma distribuisce anche conoscenza che altrimenti resterebbe dispersa nei thread di GitHub. Il termine vale la pena impararlo per ciò che descrive, non per chi lo promuove.
La regola che cambia tutto
C’è un principio che ricorre in ogni guida seria sull’argomento, e vale la pena fermarsi: il modello non deve mai eseguire direttamente uno strumento. Mai. Il modello restituisce una richiesta di azione strutturata, l’harness valida lo schema, controlla i permessi, esegue, e reinietta il risultato.
Sembra un dettaglio implementativo. È invece il punto in cui si gioca la sicurezza di un sistema agentico in azienda. Se l’agente può chiamare arbitrariamente comandi, basta una prompt injection ben costruita dentro un documento che l’agente legge, e quel comando viene eseguito con i permessi dell’agente. Il livello di mediazione, la validazione tra l’intenzione del modello e l’azione sul mondo, è ciò che distingue un assistente da un rischio operativo che gira con le credenziali aziendali.
Le tassonomie di rischio più mature classificano le azioni: sola lettura, finanziarie, distruttive. Per ognuna una matrice di permessi diversa. È il tipo di ingegneria noiosa che non finisce nei keynote e che decide se il progetto sopravvive al primo incidente.
Quattordicimila parole perse in un colpo solo
Avevo costruito un agente editoriale che lavora sul mio blog via MCP, e per settimane ha funzionato. Poi un giorno, su un articolo molto lungo, una singola operazione ha sovrascritto un post intero perché lo strumento che usavo riscriveva l’intero corpo invece di toccare il blocco giusto. Quattordicimila parole perse in un colpo. Il modello aveva ragionato benissimo, l’harness intorno non aveva il vincolo che serviva.
Da lì ho imparato sulla mia pelle quello che le aziende stanno scoprendo su scala enterprise: la fragilità non sta nell’intelligenza del modello, sta nell’assenza di guardrail attorno alle sue azioni. Avevo dovuto cambiare strategia, passare a edit chirurgici con verifica a vuoto prima di ogni scrittura, salvare lo stato prima di toccarlo. Harness engineering applicato a una redazione di una persona sola.
Birgitta Böckeler, in un modello mentale pubblicato ad aprile 2026, descrive l’harness come una combinazione di guide in avanti e sensori di ritorno che si autocorreggono prima che l’output arrivi sotto gli occhi di un umano. Distingue i controlli computazionali, i linter, i test, dalle verifiche inferenziali, un modello che giudica un altro modello. Chiude con una proposta netta: la harnessability, la capacità di un sistema di essere imbrigliato in modo affidabile, dovrebbe diventare un criterio di prima classe nelle decisioni di architettura. Alla pari del costo e delle prestazioni.
L’etica nascosta in un livello di software
Qui il discorso esce dall’ingegneria ed entra in un territorio che mi interessa da tempo. In Pelle Digitale ho provato a descrivere lo strato sottile dove l’umano e la macchina si toccano, la mediazione che decide cosa passa e cosa no. L’harness è esattamente questo, portato dentro l’azienda: il punto in cui decidiamo quanta autonomia diamo a un sistema, dove mettiamo i confini, cosa l’agente può fare da solo e cosa deve passare da una mano umana.
Le scelte che sembrano tecniche sono scelte di governance: quali azioni richiedono conferma, quali log conservare e per quanto tempo, visto che la memoria di un agente che processa dati personali resta soggetta a GDPR come qualsiasi altro trattamento, e chi risponde quando l’agente sbaglia. Domande che nessun modello, per quanto grande, risolve da solo: si affrontano progettando con cura il guscio che gli sta intorno.
Avevo già osservato come Anthropic abbia spostato l’esecuzione degli agenti dentro l’azienda lasciando la regia fuori, con sandbox self-hosted e tunnel MCP. Quella mossa ha senso solo se chi la riceve sa costruire l’harness dalla propria parte del confine. Il fornitore ti dà il motore e parte dell’infrastruttura, il resto è responsabilità tua.
Prodotto, non collante
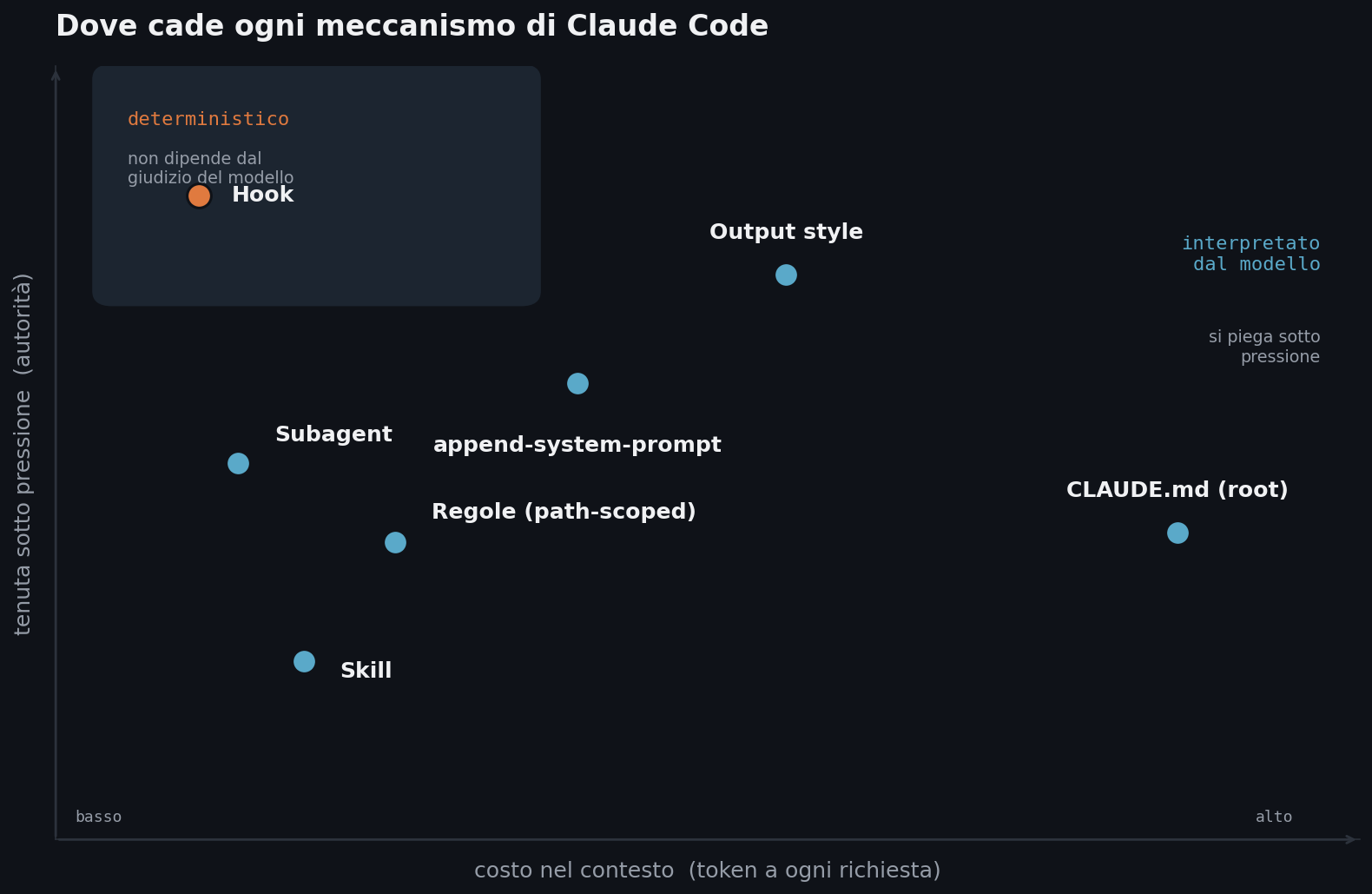
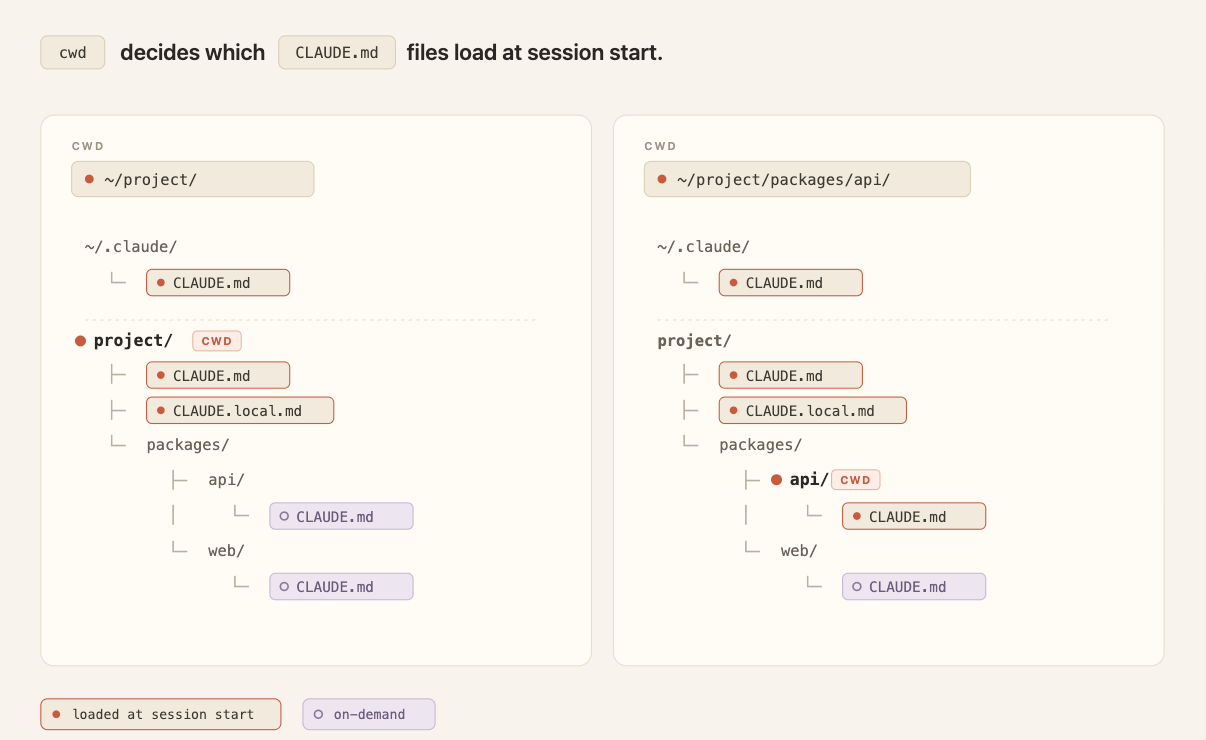
La soglia di accesso a un harness funzionante è più bassa di quanto sembri. Nick T., ricercatore che ha documentato la costruzione di un harness senza toccare una riga di codice, mette la cosa in modo diretto: chiunque può aggiungere file Markdown a un repository e sentire la differenza già dalla sessione successiva. Il CLAUDE.md o l’AGENTS.md nella root del progetto viene caricato dal modello all’avvio come un briefing. Le convenzioni di naming, i comandi di build, le cose da non fare: tutto scritto una volta, disponibile a ogni sessione senza doverlo ripetere. Primo strato, non l’intero edificio, ma quello che separa il ripartire da zero ogni volta dall’avere un agente che sa già dove si trova.
Trattate l’harness come prodotto, non come collante. La tentazione è incollare insieme un framework open e qualche script. Funziona finché non smette, di solito al primo carico reale. Le aziende che scalano comprano la plumbing commodity, runtime gestiti e telemetria di base, e costruiscono in casa la parte proprietaria che riguarda i loro dati e i loro permessi.
Mettete l’osservabilità prima dell’autonomia. Un agente che fa cose senza che voi possiate ricostruire cosa ha fatto è un debito tecnico travestito da innovazione. Prima i log strutturati e i sensori, poi l’allargamento dei poteri.
Testate l’harness, non solo il modello. Le valutazioni di sicurezza serie non si limitano a controllare le risposte del modello: provano l’infrastruttura con injection, timeout, sovraccarico di strumenti. Il punto debole è quasi sempre lì.
L’harness engineering non elimina i rischi degli agenti autonomi, li rende governabili. È una differenza che conta, perché governabile significa che qualcuno può rispondere delle decisioni del sistema, e in azienda è esattamente la domanda da cui parte tutto il resto. Quanta autonomia siamo disposti a dare a un sistema di cui capiamo, fino in fondo, solo il guscio? Se l’argomento vi tocca da vicino, è il genere di domanda su cui lavoro con CEO e CTO ogni settimana.
Spunto dall’analisi di Adnan Masood sul control plane degli agenti, dal modello mentale di Birgitta Böckeler sull’harness engineering e dall’analisi di Akshay Kokane su Agent Harness Is Just System Design With a New Name (Level Up Coding) e dall’analisi pratica di Nick T. su Harness Engineering: A Deep Dive Into the Buildable Harness via Markdown Files (AI Advances).