Claude Code orchestra i suoi agenti: dynamic workflows e la riscrittura di Bun
Il 28 maggio 2026 Anthropic ha aperto in research preview i dynamic workflows dentro Claude Code, disponibili su CLI, app desktop, estensione VS Code e via API su Bedrock, Vertex AI e Microsoft Foundry. La meccanica, descritta nel comunicato, è che Claude scrive al volo uno script di orchestrazione e lo esegue lanciando da decine a centinaia di subagent in parallelo nella stessa sessione, verificando il proprio lavoro prima che qualcosa arrivi a te. Per chi guida un’azienda che sta valutando dove mettere l’AI nel proprio stack, la notizia non è il numero di agenti, è cosa cambia nel modo in cui un problema grande viene scomposto e chiuso.
Ci ho ragionato per qualche giorno prima di scriverne, perché la prima reazione, leggendo “centinaia di agenti in parallelo”, è di archiviarlo come l’ennesima demo da keynote. Poi ho guardato il caso che Anthropic mette in cima al post, e il caso è meno comodo di quanto sembri.
Il salto rispetto al singolo agente
Fino a ieri il modello mentale era lineare: un agente legge il contesto, ragiona, agisce, controlla, e quando il compito è troppo grande lo spezzi tu, a mano, in pezzi che la finestra di contesto riesce a tenere. Funziona finché il piano sta in tre o quattro passaggi. Smette di funzionare quando il lavoro tocca migliaia di file, o quando lo stesso problema va affrontato da angoli indipendenti per essere affidabile.
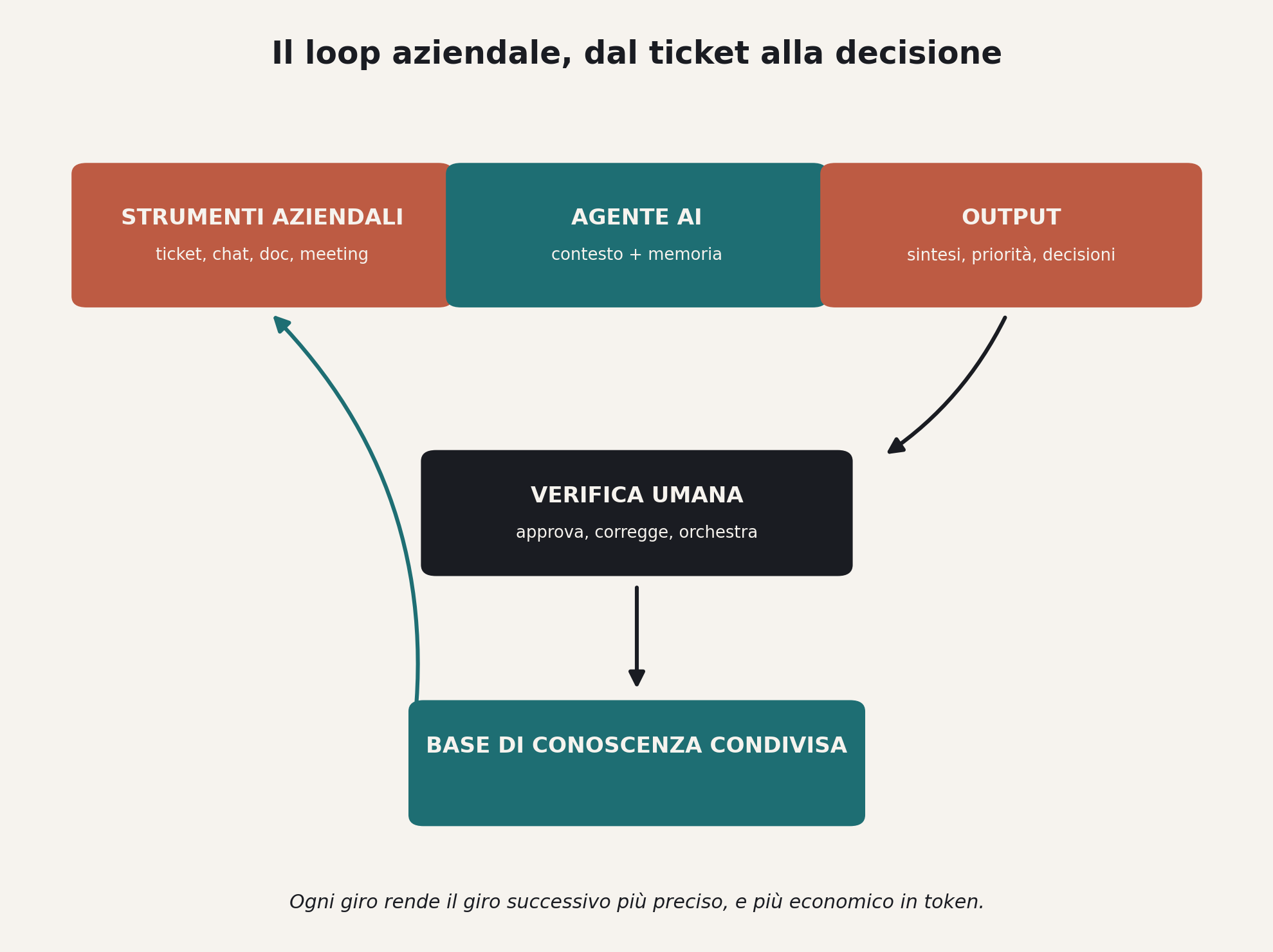
Un dynamic workflow ribalta l’ordine. Claude parte dalla richiesta in linguaggio naturale, pianifica il lavoro e lo scompone in sottocompiti, distribuendoli su subagent che girano in parallelo. I risultati vengono controllati prima di essere ricomposti. Agenti diversi attaccano il problema da prospettive indipendenti, altri agenti provano a smontare quello che i primi hanno trovato, e il ciclo itera finché le risposte convergono. La coordinazione avviene fuori dalla conversazione, in uno script che gira in background, e questo è il dettaglio architetturale che conta: il piano resta in piedi a prescindere da quanto cresce il compito, e un lavoro interrotto riprende da dove si era fermato invece di ripartire da zero.
Pasquale Pillitteri, in una delle prime analisi tecniche italiane, l’ha sintetizzato bene: nessun modello nuovo, nessun plugin, soltanto uno scarto architetturale sottile per cui Claude scrive uno script di orchestrazione in JavaScript a partire dalla richiesta, mentre un runtime separato lo esegue in background.
Bun, ovvero il caso scomodo
L’esempio che Anthropic porta come prova è la riscrittura di Bun, il runtime JavaScript alternativo a Node. Jarred Sumner ha usato i dynamic workflows per portare Bun da Zig a Rust: circa 750.000 righe di Rust, il 99,8% della test suite esistente che passa, undici giorni dal primo commit al merge. Un workflow ha mappato il lifetime Rust corretto per ogni campo di ogni struct nel codice Zig. Quello successivo ha riscritto ogni file .rs come port a comportamento identico del corrispettivo .zig, con centinaia di agenti in parallelo e due reviewer su ciascun file. Un fix loop ha poi guidato build e test fino a farli girare puliti. Dopo il merge, un workflow notturno ha aperto una pull request per ogni copia di dati superflua, lasciando la revisione finale a un umano.
Numeri da capogiro. Solo che la storia ha un’altra metà che il comunicato non racconta, e che vale la pena conoscere prima di firmare un budget su questa promessa.
Quando il branch è apparso a fine aprile, la community degli sviluppatori è esplosa: oltre 700 voti e 500 commenti su Hacker News in poche ore. Sumner stesso, il 5 maggio, scriveva su quel thread che era tutto un’esagerazione, che non c’era nessun impegno a riscrivere, e che c’era un’alta probabilità che il codice venisse buttato via del tutto. Non è andata così, il merge è arrivato il 14 maggio. Però le critiche tecniche restano sul tavolo: alcuni vecchi test sarebbero stati modificati perché la versione Rust li superasse, e l’uso della keyword unsafe da parte di Claude rende meno solida la promessa di sicurezza sulla memoria che il passaggio a Rust dovrebbe garantire. heise riporta che le issue su GitHub hanno iniziato ad accumulare i primi problemi che con la versione Zig non si presentavano.
Tengo insieme le due cose di proposito. Il workflow ha prodotto in undici giorni un risultato che a mano avrebbe richiesto trimestri, ed è una capacità reale. E allo stesso tempo il “99,8% dei test passa” significa qualcosa di diverso se una parte di quei test è stata adattata, e “non ancora in produzione” è una postilla che pesa. Chi valuta questa tecnologia per la propria azienda deve guardare entrambe le metà.
Piani che diventano codice
La regola operativa che emerge dalla documentazione e dall’uso reale è semplice. Se il piano sta in due o tre passaggi che Claude tiene in testa, restano migliori i subagent o le skill. Quando il piano diventa codice, ripetibile, scalabile a centinaia di operazioni indipendenti, allora ha senso un workflow.
I casi d’uso che Anthropic e i suoi clienti early access citano cadono tutti dentro questa logica. Bug hunt su un intero servizio, con verifica indipendente su ogni finding così che il report contenga problemi veri e non rumore. Audit di sicurezza e di ottimizzazione guidati dal profiler. Migrazioni e modernizzazioni che toccano migliaia di file, swap di framework, deprecazioni di API, port da un linguaggio all’altro. E il lavoro critico che vuoi controllato due volte, dove il costo di una risposta sbagliata è alto e quindi metti agenti avversari a provare a rompere il risultato prima che tu lo veda.
Alessio Vallero di Klarna, citato nel comunicato, racconta di aver avuto risultati forti nell’identificare codice morto e opportunità di pulizia che l’analisi statica tradizionale non vedeva. Ken Takao di CyberAgent dice che i workflow riempiono lo spazio tra il lanciare un singolo subagent e il costruire un team di agenti completo, e che il passaggio dal piano all’implementazione scorre senza perdere visibilità. Sono testimonianze di parte, fa parte del gioco di un lancio, ma descrivono un perimetro d’uso coerente: discovery e review su codebase grandi e legacy.
Il conto da tenere d’occhio
Qui arriva l’avvertenza che Anthropic, in modo per certi versi inusuale, mette nero su bianco fin dal lancio. Un dynamic workflow consuma molti più token di una sessione tipica di Claude Code. La raccomandazione esplicita è di partire da un compito circoscritto per farsi un’idea del consumo, prima di lanciarsi su lavori grandi. La prima volta che un workflow si attiva, Claude Code mostra cosa sta per girare e chiede conferma. Gli amministratori di un’organizzazione possono disabilitarlo dalle impostazioni gestite, e sui piani Enterprise è spento di default al lancio.
C’è anche un tetto: i workflow sono limitati a 1.000 subagent. Per attivarli, due strade: chiedere a Claude di creare un workflow, oppure accendere ultracode, l’impostazione specifica di Claude Code che porta l’effort a xhigh e lascia decidere a Claude quando usare un workflow.
Per un CIO italiano la traduzione è questa. La capacità tecnica è notevole e va provata, su un perimetro ristretto e misurabile, con un occhio fisso sul consumo. Il governo della spesa diventa parte integrante della governance dell’AI, non un dettaglio amministrativo, perché uno strumento che lancia centinaia di agenti autonomi su una codebase è potente esattamente quanto è capace di bruciare budget se lasciato senza confini. È la stessa logica di cui scrivo da tempo quando parlo di vendor lock-in nei progetti AI enterprise: la potenza di uno strumento non è mai gratis, e il costo nascosto si paga dopo.
La pianificazione delegata, la verifica no
L’orchestrazione di agenti che si controllano a vicenda è un cambio di postura rispetto a tutto ciò che abbiamo usato finora. Una macchina che genera ipotesi, ne mette altre a confutarle, e consegna solo quello che sopravvive al confronto, assomiglia più a un metodo di lavoro che a un autocomplete sofisticato. In Pelle Digitale ho provato a descrivere la frontiera tra la persona e la macchina come una superficie di mediazione, e questo è un punto preciso lungo quella superficie: il momento in cui smettiamo di guidare l’AI passo per passo e iniziamo a delegarle la pianificazione, tenendo per noi la verifica finale e la responsabilità.
Resta da capire quanto regge fuori dalle demo. Il caso Bun mostra cosa è possibile e, insieme, cosa va verificato a mano dopo. Per le aziende medie italiane, quelle che seguo da vicino nel mio lavoro di advisory, la domanda non è se questa tecnologia funziona, perché in parte funziona già. La domanda è dove conviene puntarla, con quale budget, e con quale presidio umano sul risultato finale.
Senza dubbio è uno degli annunci più densi degli ultimi mesi per chi costruisce software. Quello che mi interessa osservare è un’altra cosa: quanto di questa capacità arriverà nelle mani di chi sviluppa codice ogni giorno in un’azienda normale, e quanto invece resterà confinato ai casi estremi da comunicato.
Fonte: Anthropic, Introducing dynamic workflows in Claude Code, 28 maggio 2026.