
Il 18 giugno 2026 Anthropic ha pubblicato una mappa di tutti i modi in cui si può dire a Claude Code come comportarsi. Sono sette, e la cosa interessante non è l’elenco, è che ognuno di quei sette modi risponde a tre domande diverse: quando l’istruzione entra in memoria, se ci resta quando la sessione si allunga, e quanto è vincolante. Lavoro con questi agenti tutti i giorni, e ho imparato che la maggior parte degli errori di configurazione nasce dall’aver messo l’istruzione giusta nel posto sbagliato.
Per chi scrive codice da solo è una questione di efficienza. Per chi porta la responsabilità della tecnologia in un’azienda diventa qualcosa di più, perché la distanza tra un’istruzione e una garanzia è la stessa che separa una buona intenzione da una regola che nessuno può aggirare. Questa guida prova a mettere ordine: cosa sono i sette meccanismi, come si comportano quando la sessione cresce, e dove conviene scrivere ogni tipo di istruzione.
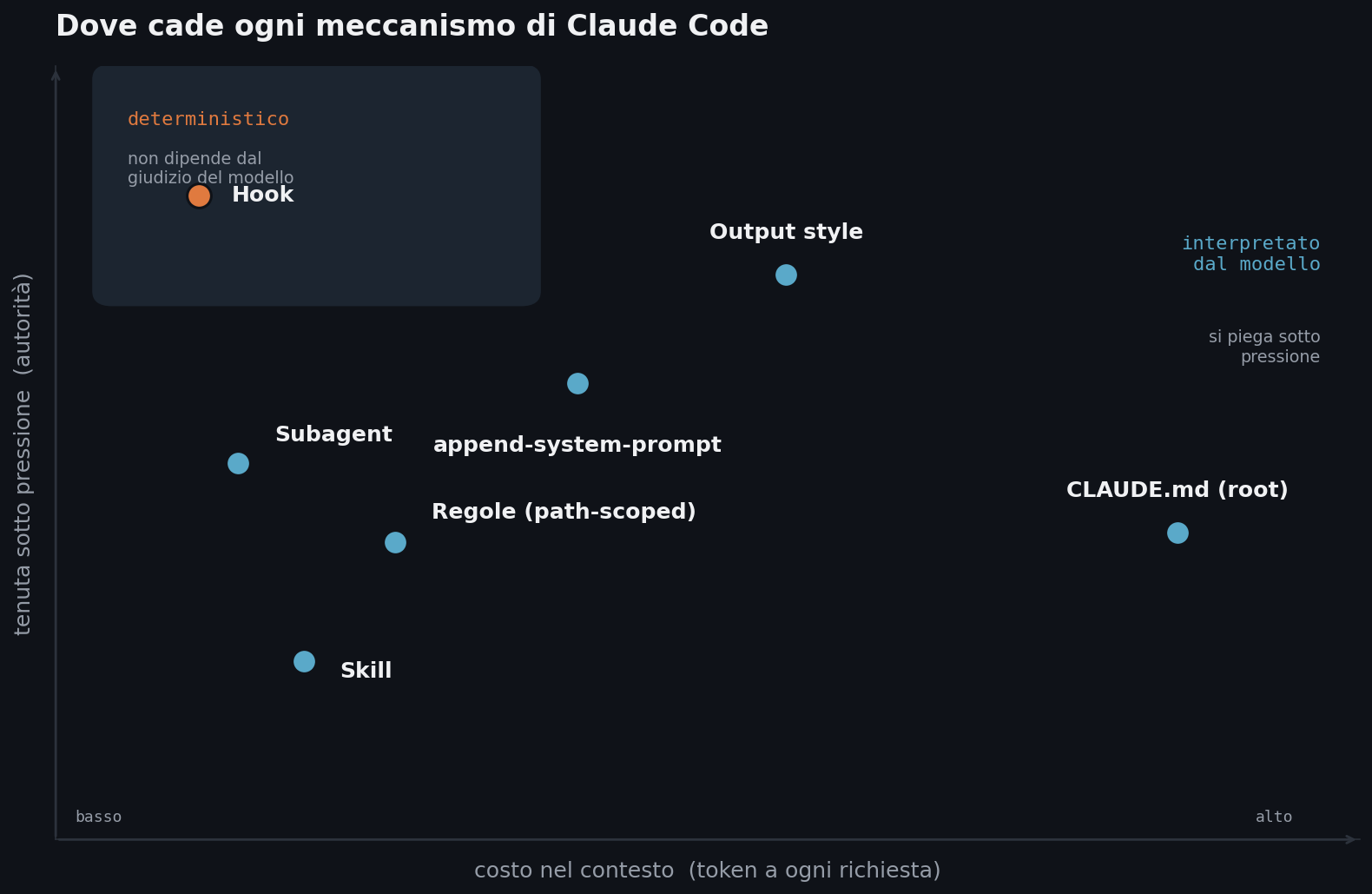
Ogni istruzione ha un costo e un’autorità
Ogni riga che finisce nella finestra di contesto di Claude occupa spazio e influenza il comportamento, e questi due effetti vanno tenuti insieme. Lo spazio è il costo: token che paghi a ogni richiesta, che l’istruzione serva o no in quel momento. L’autorità è il peso: quanto Claude segue quell’istruzione quando le cose si complicano, in una sessione lunga, in una situazione ambigua, o quando un file letto durante il lavoro contiene istruzioni nascoste che spingono in direzione opposta.
I sette meccanismi si distribuiscono lungo questi due assi. Alcuni costano molto e valgono sempre, altri costano poco perché entrano in scena solo quando servono, altri ancora non vivono affatto nel contesto perché sono codice che gira per conto suo. Sapere dove cade ciascuno è metà del lavoro. L’altra metà è una sola domanda, che torna a ogni scelta: questa cosa deve succedere quando il modello decide di farla, o deve succedere e basta?
CLAUDE.md, il file che Claude rilegge a ogni avvio
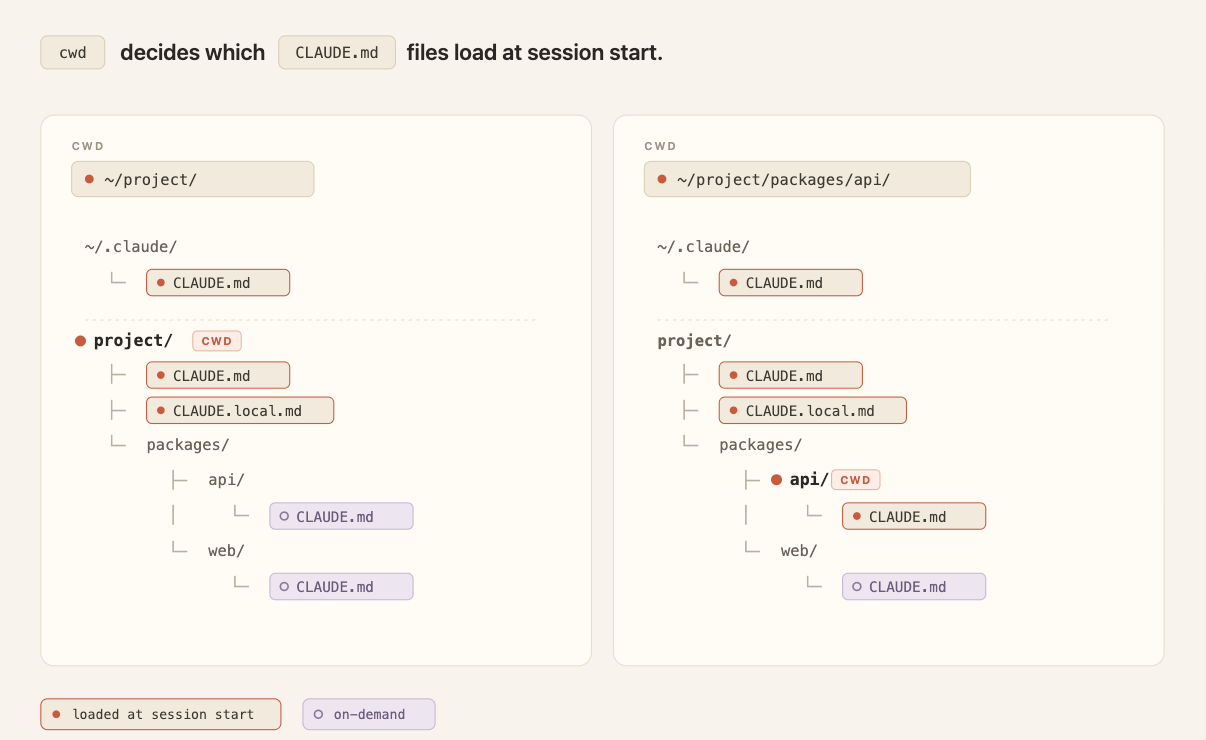
Il CLAUDE.md è un file markdown nella radice del progetto. Si carica all’inizio della sessione e ci resta per tutta la durata. Comandi di build, struttura delle cartelle, organizzazione di un monorepo, convenzioni di codice, norme del team: tutto questo sta bene qui, perché sono fatti che Claude deve avere sempre sottomano.
Ne esistono due tipi, e si comportano in modo opposto. Quello nella radice è sempre presente, sopravvive alle sessioni lunghe, e quando Claude Code comprime la conversazione per liberare spazio lo rilegge da capo. Quelli nelle sottocartelle invece si caricano su richiesta, solo quando Claude legge un file dentro quella cartella. Un app/api/CLAUDE.md non entra all’avvio, entra quando si tocca qualcosa sotto app/api, e sparisce di nuovo finché non si torna lì.
Il problema del file nella radice arriva con la scala. In un repository condiviso cresce come ogni configurazione senza padrone: ogni team aggiunge le sue righe, nessuno cancella niente, e quel testo si carica in ogni sessione di ogni persona, che riguardi il suo lavoro o no. Si pagano token, e si diluisce l’aderenza alle istruzioni che contano.
Il consiglio di Anthropic è di tenerlo sotto le duecento righe, dargli un proprietario, e trattarne le modifiche come si tratta il codice, con una revisione. Pensa a questo file come a un indice: una mappa del progetto che rimanda ad altri file dove Claude trova il dettaglio quando gli serve. Per le regole che devono valere su ogni repository dell’organizzazione, politiche di sicurezza o requisiti di conformità, esiste un CLAUDE.md gestito centralmente, distribuito sulle macchine via MDM, che il singolo non può escludere.
Le regole si caricano solo dove servono
Le regole sono file markdown dentro .claude/rules/, e danno a Claude vincoli o convenzioni precise. Senza un raggio d’azione si comportano come il CLAUDE.md: caricate all’avvio, rimesse dentro dopo ogni compressione, sempre presenti anche quando il compito non le riguarda.
Con il campo paths nell’intestazione cambia il momento del caricamento. Una regola legata a src/api/** resta fuori dal contesto durante una sessione che tocca solo la documentazione, e si carica unicamente quando Claude legge un file dentro quella cartella. L’intestazione si scrive così:
---
paths:
- "src/api/**"
- "**/*.handler.ts"
---
Ogni handler API deve validare l'input con Zod prima di processarlo.Un vincolo legato a un file specifico, tipo le migrazioni che si possono solo aggiungere e mai modificare, sta bene come regola con il suo paths. Conviene preferire una regola con raggio d’azione a un CLAUDE.md annidato quando l’istruzione riguarda un aspetto trasversale, o un tipo di file che compare in più punti del codice ma non ovunque.
Le skill portano dentro la procedura al momento giusto
Le skill vivono in .claude/skills/, cartelle che contengono istruzioni, script e risorse, ognuna con un file SKILL.md fatto di nome, descrizione e corpo. All’avvio della sessione si caricano solo il nome e la descrizione. Il corpo entra quando la skill viene invocata, con un comando slash come /code-review oppure perché Claude riconosce che il compito corrisponde a quella descrizione.
/code-review è una skill già inclusa: legge le modifiche correnti e riporta cosa ha trovato senza toccare i file. La skill definisce il copione, e Claude segue lo stesso percorso ogni volta che la richiami. Quando la conversazione viene compressa, le skill già invocate vengono rimesse dentro fino a un tetto di token condiviso tra tutte: se ne hai usate molte nella stessa sessione, le più vecchie cadono per prime.
La regola pratica è corta. Le istruzioni procedurali, un flusso di deploy o una checklist di rilascio, stanno in una skill, non nel CLAUDE.md. Claude Code arriva con le sue skill, ma puoi scriverne di tue, ed è proprio quello che faccio per il lavoro editoriale e di consulenza, impacchettando in una cartella le procedure che ripeto.
Un agente separato per il lavoro che non vuoi leggere
I subagent sono file markdown in .claude/agents/, e definiscono assistenti isolati per compiti laterali. Ogni file ha un’intestazione YAML, nome e descrizione più eventuali campi per il modello e per gli strumenti a cui può accedere, seguita da un corpo che diventa il prompt di sistema di quel subagent.
Somigliano alle skill, perché all’avvio si caricano nome, descrizione ed elenco degli strumenti, mentre il corpo non si attiva da solo: Claude lo chiama tramite lo strumento Agent passandogli un prompt. La differenza vera è l’isolamento. Il corpo del subagent non entra mai nella conversazione principale. Il subagent gira in una finestra di contesto tutta sua, e al termine torna alla sessione madre solo il suo messaggio finale, spesso il risultato aggregato di molti passaggi, più qualche metadato.
Questo schema scala in un modo che vale la pena capire. I subagent si annidano fino a cinque livelli, e i flussi di lavoro dinamici orchestrano da decine a centinaia di agenti in background senza che tu debba specificare ogni dettaglio. Il piano di orchestrazione e i risultati intermedi vivono dentro variabili di script invece che nel contesto di Claude, e questo permette di crescere senza perdere fedeltà alle istruzioni.
L’isolamento è il motivo principale per scegliere un subagent invece di una skill. Lo usi quando un compito laterale, una ricerca profonda o l’analisi di un log ingombrerebbe la conversazione principale con risultati intermedi che non riguarderai più. Usi una skill quando vuoi che la procedura si svolga dentro il thread principale, sotto i tuoi occhi, un passaggio alla volta. La documentazione sui subagent entra nel dettaglio dei campi dell’intestazione e dei permessi sugli strumenti.
Gli hook girano fuori dal contesto
Gli hook sono comandi, endpoint HTTP o prompt che danno un controllo più deterministico sul comportamento di Claude, perché scattano su eventi precisi del suo ciclo di vita: una modifica a un file, una chiamata a uno strumento, l’avvio della sessione. Si registrano nel settings.json, nelle impostazioni gestite, o nell’intestazione di una skill o di un agente.
Ne esistono di cinque tipi: command, HTTP, mcp_tool, prompt e agent. Tutti scattano in modo deterministico, ma i primi tre eseguono codice, mentre prompt e agent usano il giudizio di Claude invece di una regola fissa per decidere l’output. Il costo in contesto è basso, perché la configurazione vive fuori dalla finestra principale. Qualche output può rientrare: l’errore di un hook che blocca un’operazione viene salvato nel contesto, così Claude sa perché la chiamata è stata negata. La maggior parte degli hook invece non lascia traccia, a meno che la configurazione non lo preveda. Se hai salvato la cronologia della chat in un altro file prima della compressione usando l’evento PreCompact, Claude non saprà in quale file l’hai messa.
È qui che gli hook si staccano dal CLAUDE.md, dalle regole e dalle skill. Servono per tutto ciò che deve accadere in modo deterministico: far girare un linter dopo ogni modifica, scrivere su Slack a lavoro finito, bloccare certi comandi prima che partano. Un hook PreToolUse può ispezionare qualunque chiamata a uno strumento e uscire con codice 2 per negarla. Costano poco perché sono codice che l’ambiente esegue, non istruzioni che Claude deve caricare e interpretare.

Output style e system prompt: l’autorità più alta
Gli output style sono file in .claude/output-styles/ che iniettano istruzioni nel prompt di sistema. Non vengono mai compressi, si caricano all’inizio di ogni sessione, e dopo la prima richiesta restano in cache, quindi il costo in contesto è moderato. Stando nel prompt di sistema portano il peso di aderenza più alto tra tutti i metodi visti finora, e vanno usati con misura.
C’è una trappola. Cambiare l’output style sostituisce quello predefinito, a meno che tu non imposti keep-coding-instructions: true nell’intestazione. In Claude Code questo cancella le istruzioni che dicono a Claude di star aiutando con un lavoro di ingegneria del software, e con loro abitudini critiche come quando aggiungere o togliere commenti al codice, come gestire le questioni di sicurezza, l’abitudine a far girare i test prima di dichiarare finito un lavoro. Senza accorgertene, Claude Code diventa un assistente generico invece di un assistente che programma. Prima di scriverne uno tuo, conviene guardare quelli già inclusi: Proactive, Explanatory e Learning coprono i bisogni più comuni.
L’alternativa più leggera è il flag append-system-prompt. Dove modificare un output style può avere effetti larghi e non voluti, il flag è solo additivo: non cambia il ruolo di Claude, gli aggiunge istruzioni. Si passa al momento dell’invocazione e vale solo per quella, non resta come file tra le sessioni. Costa qualche token in più in ingresso, attenuato dalla cache dopo la prima richiesta, ed è la via giusta per standard di codice specifici, formati di output, conoscenza di dominio. Con un avvertimento che vale per tutti i metodi a prompt: più istruzioni infili, meno Claude le segue alla lettera, soprattutto se qualcuna contraddice le altre.
Quando l’istruzione è nel posto sbagliato
Ci sono segnali che dicono che un’istruzione andrebbe spostata altrove. Se ti ritrovi a scrivere “ogni volta che X, fai sempre Y” nel CLAUDE.md, e quel comportamento deve essere affidabile, tipo far girare prettier dopo ogni modifica, quello è un hook nel settings.json. Il modello che sceglie di lanciare un formattatore è un’altra cosa rispetto al formattatore che parte da solo.
Se nel CLAUDE.md compare un “non fare mai questo”, l’istruzione è lo strumento sbagliato. Claude la seguirà quasi sempre, ma sotto pressione, in una sessione lunga, in una situazione ambigua, o per via di un’iniezione di prompt dentro un file aperto durante il compito, il modello può non rispettarla. Una barriera vera è deterministica, e si costruisce con gli hook e i permessi. Un hook PreToolUse ispeziona la chiamata ed esce con codice 2 per bloccarla. Le impostazioni gestite vanno oltre: le distribuisce un amministratore, l’utente non le può sovrascrivere, e sono l’unico modo per imporre una barriera deterministica su tutta l’organizzazione.
Una procedura di trenta righe nel CLAUDE.md va in una skill. Una regola che vale solo per src/api/** va scritta con il suo paths, perché senza è meccanicamente identica a mettere quel testo nel CLAUDE.md, sempre caricata, sempre a consumare token. E le preferenze personali, tipo usare sempre messaggi di commit semantici, vanno nei file a livello utente, che valgono per ogni sessione a prescindere dal repository, non nel file di progetto condiviso con il team.
Un’istruzione non è una garanzia
Tutto questo si riduce a una distinzione che per chi guida la tecnologia conta più di qualunque dettaglio di configurazione. Un’istruzione a prompt, stia nel CLAUDE.md o in una regola o in un output style, è una richiesta che il modello interpreta e quasi sempre rispetta. Una barriera costruita con hook e permessi è un fatto meccanico che non dipende dal giudizio del modello. La prima si piega sotto pressione, la seconda no. Quando in gioco ci sono dati sensibili, ambienti di produzione, o un comando che non deve partire mai, l’unica risposta seria è quella deterministica.
C’è anche un costo che si accumula nel tempo, e somiglia parecchio a quello di cui scrivo da mesi a proposito del debito cognitivo. Un CLAUDE.md senza proprietario cresce, e ogni riga in più si carica in ogni sessione di ogni persona, pesando sul budget di token e annacquando le istruzioni che servono. È un debito di contesto: lo paghi poco alla volta, finché un giorno la finestra è piena di righe che nessuno legge e il modello segue peggio quelle importanti. La cura è la stessa di sempre, un proprietario, una revisione, e la disciplina di spostare ogni istruzione dove il suo costo e la sua autorità corrispondono al compito.
Nei vari testi che scrivo da un po’ ho provato più volte a descrivere l’interfaccia tra la mente e gli strumenti che la estendono, e guidare un agente è proprio quel punto: il momento in cui un’intenzione umana si traduce in qualcosa che una macchina eseguirà al posto tuo. Quando hai qualcuno di questi meccanismi a posto, puoi raccoglierli insieme, skill, subagent, hook e output style, dentro un plugin, e condividere un assetto coerente con il team o tra i progetti.
Senza dubbio nei prossimi mesi questi strumenti diventeranno più semplici e più capaci. La domanda che resta aperta è chi, nella tua organizzazione, possiede la mappa di cosa Claude può e non può fare, e la tiene aggiornata mentre la finestra di contesto si riempie. Se è il genere di mappa che serve disegnare per la tua azienda, è una delle conversazioni che porto al tavolo nel mio lavoro di advisory.
Fonte: Anthropic, Steering Claude Code: CLAUDE.md files, skills, hooks, rules, subagents and more, 18 giugno 2026. Approfondimenti nella documentazione ufficiale su subagent e output style.