
Apple ha presentato Apple Intelligence alla Worldwide Developers Conference 2024. Questo sistema di intelligenza “personale”, praticamente un assistente sempre attivo sul device, sarà integrato completamente in iOS 18, iPadOS 18 e macOS Sequoia e compatibile su device Iphone 15 pro e successivi. Il sistema Apple Intelligence utilizza modelli generativi avanzati, specializzati per compiti quotidiani come la scrittura e la revisione di testi, la sintesi e la priorizzazione delle notifiche, la creazione di immagini per le conversazioni e l’esecuzione di azioni in-app per semplificare le interazioni tra le app.
Ho letto e studiato il paper pubblicato e presente a questo indirizzo con l’obiettivo di chiarirmi e chiarire meglio come funziona questo tipo di approccio.
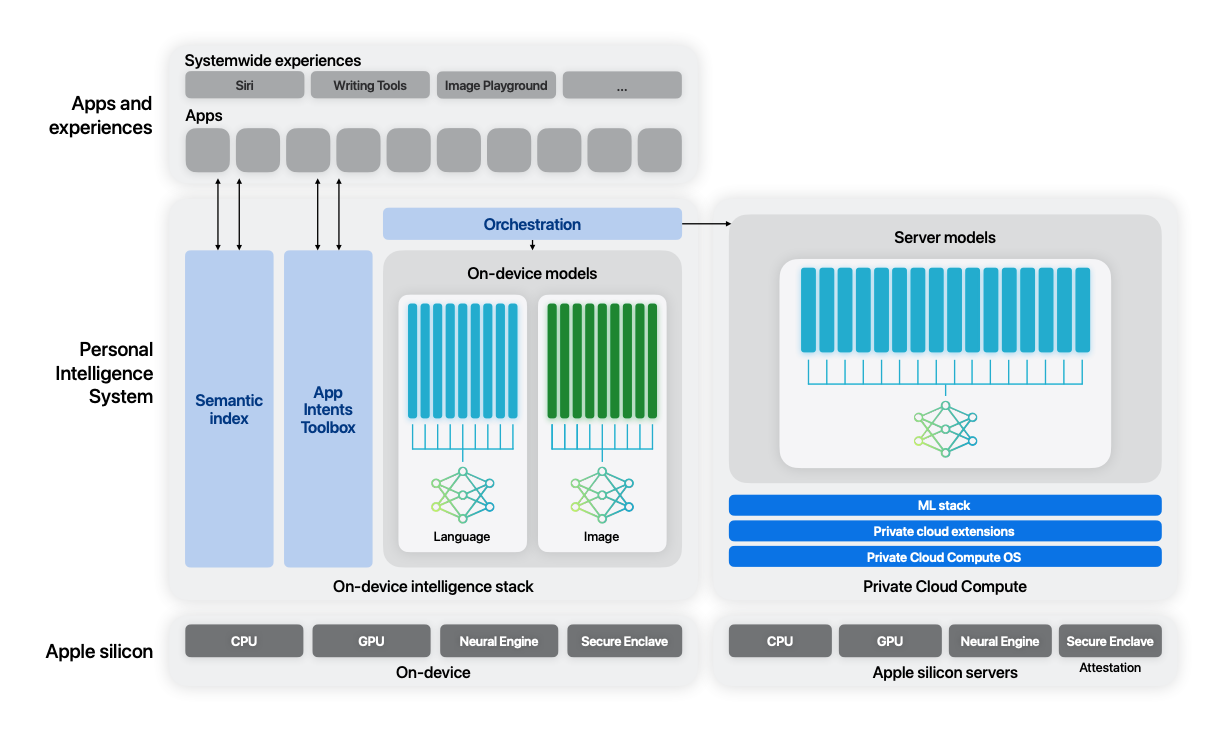
Modelli di base
Prima di tutto partiamo dai modelli utilizzati. Apple Intelligence si basa su due modelli principali: un modello linguistico on-device con circa 3 miliardi di parametri e un modello più grande basato su server. Entrambi i modelli sono progettati per offrire prestazioni elevate, segregare alcune funzioni demandabili al device e altre ad un sistema fuori dal device e garantire di conseguenza un utilizzo responsabile dei dati e dell’AI, oltre a mio avviso del consumo e impatto.
Modello On-Device
Caratteristiche tecniche:
- Parametri: Circa 3 miliardi di parametri.
- Architettura: Basato su architettura Transformer, ottimizzata per l’esecuzione locale su dispositivi Apple.
- Quantizzazione: Utilizza tecniche di riduzione della precisione, a bassa risoluzione (2-bit e 4-bit) così da ridurre i requisiti di memoria e migliorare l’efficienza energetica.
- Ottimizzazioni:
- Grouped-Query Attention (GQA): Riduce i requisiti di memoria e migliora la velocità di inferenza.
- Palletizzazione: Implementa una configurazione mista di 2-bit e 4-bit per ottenere prestazioni comparabili a quelle dei modelli non compressi.
- Talaria: Strumento interattivo di analisi della latenza e del consumo energetico per ottimizzare la selezione del bit rate in ogni operazione.
- Quantizzazione di attivazioni e embedding: Riduce ulteriormente i requisiti di memoria senza compromettere la qualità del modello.
Utilizzo: Il modello on-device è integrato direttamente nei dispositivi Apple (iPhone, iPad e Mac) per gestire compiti quotidiani come:
- Scrittura e Revisione di Testi: Assistenza nella stesura e modifica di email, messaggi e documenti.
- Sintesi e Prioritizzazione delle Notifiche: Riassume e organizza le notifiche per migliorare la gestione delle comunicazioni.
- Esecuzione di Azioni In-App: Automatizza attività e interazioni tra le app per rendere l’uso del dispositivo più intuitivo.
Modello Server-Based
Caratteristiche tecniche:
- Parametri: Modello con un numero di parametri significativamente maggiore rispetto al modello on-device, progettato per operare sui server Apple Silicon.
- Architettura: Anche questo modello si basa sull’architettura Transformer, ma è ottimizzato per l’elaborazione su larga scala nei data center.
- Vocabulario: Utilizza una dimensione del vocabolario più ampia (100.000 token) rispetto al modello on-device (49.000 token), includendo token aggiuntivi per lingue e termini tecnici.
- Ottimizzazioni:
- Parallelismo: Impiega parallelismo a livello di dati, tensor, sequenza e Fully Sharded Data Parallel (FSDP) per scalare l’addestramento su vari hardware.
- Reinforcement Learning from Human Feedback (RLHF): Utilizza algoritmi avanzati di ottimizzazione delle politiche per migliorare la qualità delle risposte del modello.
- Rejection Sampling Fine-Tuning: Metodo di campionamento con un comitato di insegnanti per migliorare la capacità di seguire istruzioni.
Utilizzo: Il modello server-based è utilizzato per gestire compiti più complessi e intensivi in termini di calcolo, beneficiando delle capacità avanzate dei data center di Apple. Esempi di utilizzo includono:
- Generazione di Contenuti Complessi: Creazione di testi dettagliati e specifici su richiesta degli utenti.
- Analisi Avanzata dei Dati: Esecuzione di elaborazioni intensive come l’analisi approfondita dei dati.
- Supporto ai Servizi Cloud: Fornisce potenza di calcolo per applicazioni e servizi che richiedono un’elaborazione continua e intensiva.
Integrazione nei Processi di Apple Intelligence
Apple Intelligence integra questi modelli in un sistema coeso per offrire una vasta gamma di funzionalità intelligenti. Questo processo coinvolge:
- Identificazione del Compito: Riconosce il tipo di attività che l’utente sta cercando di eseguire e decide se può essere gestita localmente o richiede il supporto del modello server-based.
- Selezione del Modello: Determina quale modello utilizzare in base alla complessità e ai requisiti del compito. Compiti quotidiani semplici vengono gestiti dal modello on-device, mentre compiti complessi vengono indirizzati al modello server-based.
- Esecuzione e Ottimizzazione: Il modello selezionato esegue il compito utilizzando ottimizzazioni specifiche per garantire velocità e precisione.
- Risposta e Feedback: Fornisce i risultati all’utente e raccoglie feedback per migliorare continuamente i modelli.
- Aggiornamenti e Manutenzione: I modelli sono costantemente aggiornati per migliorare le prestazioni e mantenere la sicurezza.
Questa architettura garantisce che Apple Intelligence possa offrire un’esperienza utente fluida, potente e sicura, sfruttando al meglio le capacità sia dei dispositivi locali che dell’infrastruttura cloud di Apple.
3. Sviluppo responsabile dell’IA
Apple segue una serie di principi di AI responsabile che guidano lo sviluppo di Apple Intelligence:
- Empowerment degli utenti:
- Apple si impegna a identificare aree in cui l’intelligenza artificiale può essere utilizzata responsabilmente per creare strumenti che rispondano a bisogni specifici degli utenti.
- Rispetta le modalità in cui gli utenti scelgono di utilizzare questi strumenti per raggiungere i loro obiettivi, garantendo che l’IA sia uno strumento di potenziamento piuttosto che di controllo.
- Rappresentazione autentica degli utenti:
- L’obiettivo di Apple è creare prodotti che rappresentino autenticamente gli utenti di tutto il mondo, evitando di perpetuare stereotipi e bias sistemici.
- Apple lavora continuamente per identificare e mitigare qualsiasi forma di bias nei loro modelli di intelligenza artificiale, assicurando una rappresentazione equa e inclusiva.
- Design attento:
- Apple prende precauzioni in tutte le fasi del processo di sviluppo dell’IA, inclusi il design, l’addestramento dei modelli, lo sviluppo delle funzionalità e la valutazione della qualità.
- Si impegna a identificare e prevenire potenziali usi impropri o dannosi degli strumenti di IA, migliorando proattivamente questi strumenti attraverso il feedback degli utenti.
- Protezione della privacy:
- Apple utilizza processi on-device e infrastrutture come il Private Cloud Compute per proteggere la privacy degli utenti.
- Non utilizza i dati personali privati degli utenti o le loro interazioni per addestrare i modelli di base, applicando filtri per rimuovere informazioni identificabili come numeri di previdenza sociale o di carte di credito.
4. Addestramento dei modelli
I modelli di base di Apple sono addestrati utilizzando il framework AXLearn, un progetto open-source basato su JAX e XLA, che permette un addestramento efficiente e scalabile.
- Efficienza e Scalabilità:
- AXLearn consente l’addestramento su vari hardware e piattaforme cloud, inclusi TPU e GPU sia in cloud che on-premise.
- Apple utilizza tecniche come data parallelism, tensor parallelism, sequence parallelism e Fully Sharded Data Parallel (FSDP) per scalare l’addestramento su più dimensioni.
- Strategia Ibrida dei Dati:
- Apple combina dati annotati manualmente con dati sintetici e implementa procedure di curation e filtraggio rigorose per garantire la qualità del training data.
- Apple filtra informazioni personali e contenuti di bassa qualità dal corpus di addestramento, utilizzando un classificatore basato su modelli per identificare documenti di alta qualità.
- Algoritmi di Post-Training:
- Rejection Sampling Fine-Tuning: Apple utilizza un algoritmo di campionamento con un comitato di insegnanti per migliorare la capacità del modello di seguire le istruzioni.
- Reinforcement Learning from Human Feedback (RLHF): Un algoritmo avanzato che utilizza la politica di discesa speculare e un estimatore di vantaggio leave-one-out per migliorare la qualità delle risposte del modello.
5. Ottimizzazione
Apple applica una serie di tecniche innovative per ottimizzare i modelli, sia on-device che su server, garantendo velocità e efficienza.
- Grouped-Query Attention (GQA): Questa tecnica riduce i requisiti di memoria e migliora le prestazioni di inferenza.
- Quantizzazione:
- Low-Bit Palletization: Utilizza una configurazione mista di 2-bit e 4-bit per ottenere prestazioni comparabili ai modelli non compressi, mantenendo la qualità.
- Talaria Tool: Strumento interattivo per analizzare latenza e consumo energetico, ottimizzando il bit rate per ogni operazione.
- Quantizzazione di Attivazioni e Embedding: Riduce ulteriormente i requisiti di memoria senza compromettere la qualità del modello.
- Cache KV: Ottimizza l’aggiornamento della cache Key-Value sui motori neurali per migliorare l’efficienza.
6. Adattamento dei modelli
Apple utilizza adattatori, piccoli moduli di rete neurale, per specializzare i modelli per compiti specifici, mantenendo inalterati i parametri originali del modello base.
- Adattatori (Adapters):
- Gli adattatori sono integrati nei vari strati del modello pre-addestrato, consentendo una specializzazione dinamica per il compito attuale.
- I parametri degli adattatori sono rappresentati con 16 bit e richiedono solo pochi megabyte di memoria.
- Gli adattatori possono essere caricati dinamicamente e gestiti in memoria in modo efficiente, garantendo la reattività del sistema operativo.
- Infrastruttura per l’Addestramento degli Adattatori:
- Apple ha creato un’infrastruttura efficiente per addestrare, testare e distribuire rapidamente gli adattatori quando il modello base o i dati di addestramento vengono aggiornati.
7. Valutazione delle prestazioni
Apple valuta le prestazioni dei modelli tramite benchmark e valutazioni umane, concentrandosi sull’utilità per l’utente finale.
- Benchmarking:
- Apple utilizza un set completo di prompt reali per testare le capacità generali del modello, coprendo categorie come brainstorming, classificazione, codifica, ragionamento matematico e sicurezza.
- Le valutazioni dimostrano che i modelli Apple spesso superano i modelli comparabili in termini di accuratezza e capacità di seguire le istruzioni.
- Valutazioni di Specifiche Funzionalità:
- Apple utilizza adattatori per ottimizzare le prestazioni su compiti specifici, come la sintesi di email, messaggi e notifiche.
- Le valutazioni includono anche test su set diversificati di input rappresentativi dei casi d’uso reali.
8. Risultati di performance
Le valutazioni mostrano che i modelli Apple sono preferiti dai valutatori umani rispetto ai modelli concorrenti in vari compiti.
- Comparazione con Modelli Competitor:
- I modelli on-device di Apple con ~3 miliardi di parametri superano modelli più grandi come Phi-3-mini, Mistral-7B, Gemma-7B e Llama-3-8B.
- I modelli server di Apple si confrontano favorevolmente con modelli commerciali come GPT-3.5, GPT-4 e Llama-3-70B, risultando più efficienti e sicuri.
- Risultati di Sicurezza:
- Apple utilizza prompt diversificati e avversariali per testare le prestazioni dei modelli su contenuti dannosi e argomenti sensibili, raggiungendo tassi di violazione inferiori rispetto ai modelli open-source e commerciali.
- Benchmark di Instruction-Following (IFEval):
- I modelli Apple dimostrano capacità superiori nel seguire istruzioni dettagliate rispetto ai modelli di dimensioni comparabili.
- Benchmark di Scrittura e Sintesi:
- I modelli Apple sono valutati positivamente nelle capacità di sintesi e composizione, ottenendo punteggi elevati nelle valutazioni interne.
Apple Intelligence, presentata alla WWDC 2024, è profondamente integrata nei dispositivi Apple e offre capacità potenti in ambito linguistico, visivo e di azione, sviluppate responsabilmente e guidate dai valori fondamentali di Apple. I modelli di base e gli adattatori garantiscono prestazioni elevate e sicure, migliorando l’esperienza utente in vari compiti quotidiani. Apple continuerà a condividere ulteriori informazioni sulla famiglia di modelli generativi, inclusi modelli linguistici, di diffusione e di programmazione.
A questo indirizzo è possibile leggere i paper integrale e la documentazione ufficiale. Vale la pena sse avete interesse e tempo di leggere tutto lo studio che in questo post ho sinteticamente riportato.

Comments are closed