Manus AI, la guida completa per le aziende: agente, costi, governance
Cosa significa “agente autonomo” davvero
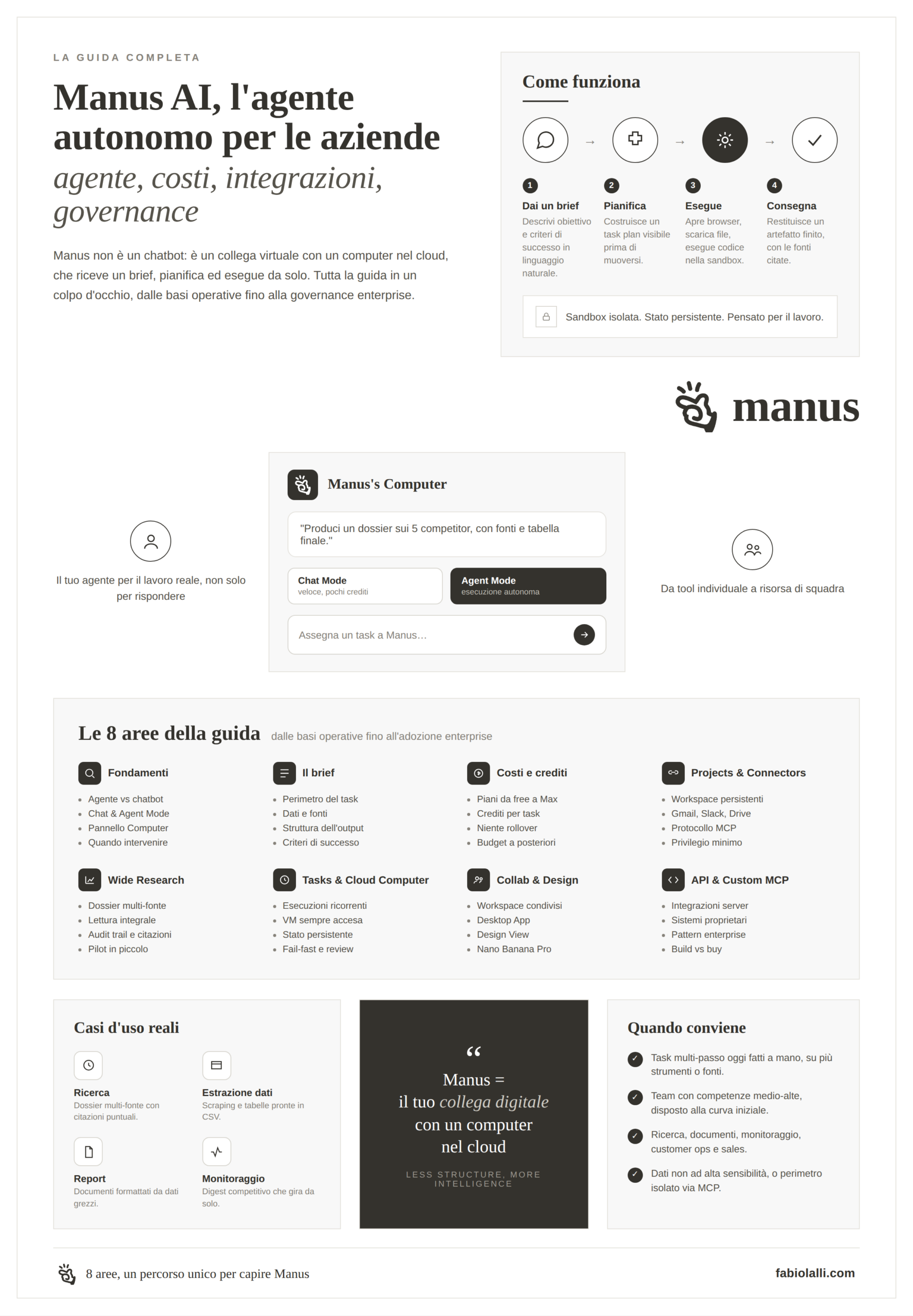
Per capire Manus AI c’è una distinzione che sembra banale e invece fa tutta la differenza. ChatGPT, Claude, Gemini sono assistenti conversazionali: il ciclo è prompt-risposta, e chi guida il processo resta sempre l’utente, che decompone il problema, lancia richieste in sequenza, ricompone i risultati a mano. Manus rompe questo schema. Riceve un brief in linguaggio naturale, costruisce un piano di esecuzione visibile, e parte da solo, pianifica i passi, apre un browser, esegue ricerche, scarica file, esegue codice, salva risultati, consegna un artefatto finale.
A raccontarlo così sembra una sfumatura semantica, in pratica è un cambio di paradigma, ed è la prima cosa da mettere a fuoco su Manus AI. La documentazione ufficiale di Manus parla di “virtual colleague with its own computer”, e l’immagine rende. L’agente vive in una sandbox Linux Ubuntu completa, con shell, file system persistente, browser Chromium, interpreti Python e Node.js, e può perfino esporre servizi web all’esterno. La parte tecnica più interessante, raccontata in dettaglio dal post di E2B che fornisce l’infrastruttura, è che ogni sessione gira su microVM Firecracker, le stesse macchine virtuali leggere sviluppate da AWS per Lambda. Il risultato pratico è che l’agente può lavorare per decine di minuti, anche un’ora, mantenendo lo stato tra un passo e l’altro, persino quando il dispositivo dell’utente è spento.
Questo cambia il modo in cui si chiede a Manus di fare qualcosa. Un prompt per ChatGPT richiede precisione sulla forma della risposta, perché il modello deve restituire un testo subito. Un brief per Manus richiede precisione sull’obiettivo finale e sui criteri di successo, perché il modello prenderà decine di micro-decisioni autonome durante l’esecuzione, senza poter chiedere conferma a ogni passaggio. È una scrittura più vicina a quella che useresti per un consulente esterno che riceve un brief e torna dopo due giorni con il dossier, non a quella che useresti per un assistente in chat. Tengo questa analogia per tutta la guida, perché è la chiave mentale che fa funzionare lo strumento.
Le due modalità e il pannello “Manus’s Computer”
Il prodotto si articola su due modalità. Chat Mode funziona come un assistente conversazionale tradizionale, costa pochissimi crediti, serve a domande veloci, sintesi rapide, ricerca puntuale. Agent Mode è la modalità autonoma vera, dove Manus prende il brief, costruisce il task plan, e parte. La differenza in termini di costi è netta, e va capita prima di iniziare a usare il prodotto in modo regolare, perché Chat Mode resta per molti utenti il novanta per cento dell’uso quotidiano.
L’elemento più distintivo dell’interfaccia è “Manus’s Computer”, un pannello laterale che mostra in tempo reale tutto ciò che l’agente sta facendo: quali pagine apre, cosa cerca, quali file scrive, quali comandi lancia nel terminale. Per chi viene da anni di chatbot dove tutto è invisibile, è un’esperienza diversa, si vede l’agente lavorare, si intercettano gli errori prima che compromettano l’intero task, si interviene spostandolo da una direzione sbagliata. Una review su Cybernews lo descrive come guardare un ricercatore al lavoro con una checklist davanti, ed è fedele.
Il punto delicato è che questa trasparenza si paga con una maggiore responsabilità di supervisione. Manus può sbagliare click sul browser, fraintendere un’istruzione, costruire un piano errato, e senza un occhio sul “Computer” l’agente consuma crediti per minuti producendo un output che alla fine non serve. La logica corretta è dargli un brief chiaro, lasciarlo lavorare, ma tenere sotto controllo i primi passi del piano. Se il piano iniziale regge, di solito l’esecuzione regge. Se è sbagliato, meglio fermarsi e riformulare. La regola pratica, ad ogni nuovo task, è chiedersi quanti strumenti diversi userei se facessi io questo lavoro: se la risposta è uno, basta Chat Mode, se sono tre o più, vale la pena passare ad Agent Mode.
Come si scrive un brief per un agente autonomo
Un brief per Manus non è un prompt per ChatGPT, ed è la singola cosa che fa la differenza tra task riusciti e task abbandonati a metà esecuzione. Un prompt conversazionale è una richiesta puntuale a cui il modello risponde subito. Un brief per Manus è la descrizione di un risultato finale e dei criteri per riconoscerlo come riuscito.
Un esempio, partendo da una richiesta sbagliata: “fammi una ricerca sui competitor”. Manus parte, ma il piano è generico, l’output incerto, i crediti consumati senza un punto di arrivo chiaro. Lo stesso task in versione corretta: “produci un dossier su cinque competitor italiani nel settore X, per ognuno raccogli sede legale, fatturato ultimi due esercizi disponibili da bilanci pubblici, posizionamento dichiarato sul sito, principali clienti citati in case study, presenza su LinkedIn dei C-level. Output: un file markdown con cinque schede da una pagina ciascuna, link a tutte le fonti, e una tabella riassuntiva finale”. Stessa richiesta sostanziale, risultato completamente diverso.
La differenza è che il secondo brief specifica quattro cose che il primo lasciava implicite: il perimetro del task, i dati da raccogliere, la struttura dell’output, le fonti accettabili. Manus eccelle quando questi quattro vincoli sono chiari, perché può costruire un piano di esecuzione lineare. Quando uno solo dei quattro manca, l’agente deve indovinare, e gli indovinelli costano crediti. La documentazione ufficiale suggerisce di pensare a sé stessi come a un manager che assegna un compito a un collaboratore esterno, ed è un’analogia che vale la pena adottare mentalmente prima ancora di iniziare a digitare. C’è anche una funzione che conviene conoscere dalla prima sessione: l’agente può essere fermato in qualsiasi momento, e si interviene chiedendo correzioni puntuali, suggerendo alternative, fornendo credenziali quando il sito richiede login. Questa pausabilità è uno dei tratti che distinguono Manus dagli agenti puramente background.
Piani, crediti, costi: il modello economico
Manus usa un sistema a crediti, e questo cambia profondamente l’esperienza rispetto agli abbonamenti illimitati di ChatGPT Plus o Claude Pro. Il piano gratuito offre trecento crediti che si rigenerano ogni ventiquattr’ore, più mille crediti starter una tantum, con accesso al Chat Mode e a Manus 1.6 Lite in Agent Mode. Basta per testare il prodotto e capire se ha senso salire di piano.
I piani Pro partono da venti dollari al mese per quattromila crediti, salgono a quaranta dollari per ottomila crediti con accesso al Wide Research, e arrivano a duecento dollari per il piano top che porta i crediti mensili a quarantamila e abilita la generazione batch di slide e siti. Il piano Team parte da venti dollari per seat con un minimo di due membri, e introduce funzionalità di workspace condiviso. La fatturazione annuale taglia circa il 17 per cento. Per i numeri aggiornati c’è la pagina ufficiale dei piani, ma il dato che conta per ragionare sui costi è un altro: i crediti mensili non si accumulano da un mese all’altro, mentre quelli acquistati come add-on restano disponibili finché l’abbonamento è attivo. Una review su Spectrum AI Lab lo conferma analizzando le regole di rollover.
Il dato concreto che serve per dimensionare il budget: un task di ricerca semplice consuma intorno ai cinquanta-sessanta crediti, un’analisi dataset di media complessità ne brucia trecento, un dossier di Wide Research approfondito arriva a quattro o diecimila crediti in una singola esecuzione. Manus non stima il costo di un task prima di lanciarlo, e in caso di crediti insufficienti si ferma a metà esecuzione senza addebiti automatici di overage. Per le aziende il budgeting va dunque fatto a posteriori nelle prime settimane, finché il team non sviluppa un’intuizione sui costi tipici dei propri task ricorrenti. Un consiglio che do sempre: tenere un piccolo log dei task lanciati, con brief, esito, crediti consumati, perché dopo dieci o quindici task emergono i pattern, alcuni tipi di richiesta rendono bene e altri sono sistematicamente difficili, e quel log diventa la base per capire dove Manus sostituisce ore di lavoro e dove invece produce solo overhead di supervisione.
I limiti veri delle prime sessioni
Manus non è perfetto, e conviene saperlo in partenza per evitare delusioni mal indirizzate. I problemi più comuni nelle prime sessioni sono tre. L’agente a volte fraintende il brief e parte in una direzione sbagliata, fa click errati sul browser scegliendo elementi che sembravano giusti, e in task lunghi perde il filo del piano iniziale divergendo verso obiettivi secondari.
Il primo problema si risolve scrivendo brief più precisi. Il secondo è una limitazione tecnica, mitigata dal browser visivo che permette di vedere gli errori e correggerli, ma resta una causa frequente di crediti consumati senza output utile. Il terzo è il più insidioso, e si gestisce dividendo i task lunghi in sotto-task più piccoli, ognuno con un output ben definito, invece di chiedere all’agente di completare in una singola esecuzione una pipeline articolata. Una review approfondita su Lindy nota che Manus funziona bene su task con percorso lineare e meno bene su quelli con logica condizionale ramificata, ed è un’osservazione utile per calibrare le aspettative fin dall’inizio.
I task su cui rodarsi senza rischiare frustrazione, nelle prime settimane, sono tre. La ricerca strutturata multi-fonte, dove Manus apre decine di pagine e le legge integralmente, producendo risultati migliori di un assistente conversazionale. L’estrazione dati da fonti web, dove l’agente apre la pagina, esegue lo scraping, scrive uno script di parsing se serve, salva il CSV, e risolve in cinque o dieci minuti quello che a mano ne richiederebbe quaranta. La generazione di documenti formattati a partire da input strutturati, dove dato un file Excel con i risultati di una survey l’agente produce un report con grafici, executive summary, sezioni per ogni domanda. Questi tre pattern coprono buona parte del valore quotidiano di Manus per un manager, e funzionano come esercizi di apprendimento.
Projects e Connectors: l’agente che entra nello stack di lavoro
Fino a metà 2025 Manus aveva un problema strutturale: ogni sessione partiva da zero. L’agente non sapeva nulla del lavoro precedente, delle abitudini del team, delle conversazioni in corso, e andava istruito ogni volta. A dicembre 2025 è arrivata la prima risposta strutturale sotto forma di Projects con Connectors, ed è il momento in cui Manus smette di essere un tool per task estemporanei e inizia a operare dentro il proprio contesto.
Un Project è un workspace persistente che conserva istruzioni di base, file di riferimento, cronologia delle conversazioni correlate. Invece di spiegare ogni volta a Manus chi siete, cosa fa la vostra azienda, qual è il tono di voce, quali sono i clienti chiave, queste informazioni vivono dentro il Project e l’agente le richiama all’inizio di ogni nuovo task. La pagina ufficiale del lancio descrive l’idea di trasformare task ripetibili in spazi persistenti. L’impatto si manifesta in tre direzioni: la qualità degli output, perché con il contesto già caricato Manus produce risultati più allineati al brand e al settore, il risparmio di crediti, perché spariscono i passi che l’agente farebbe per capire il contesto, e la possibilità di delegare task ricorrenti a chi nel team ha meno familiarità con lo strumento, perché il Project incapsula la complessità.
Qui si gioca la partita vera dei Connectors. Un Project può collegarsi nativamente, via protocollo MCP, ai servizi che già si usano: Gmail, Notion, Stripe, HubSpot, Slack, Google Calendar, Hugging Face, Google Drive, GitHub, e l’elenco continua a crescere. MCP è lo standard aperto che Anthropic ha proposto nel 2024 e che si sta affermando come lingua franca per l’integrazione tra agenti e tool esterni, un tema legato a doppio filo a come si evita il vendor lock-in nei progetti AI enterprise. Un esempio concreto: con il connettore Gmail attivo si può chiedere a Manus di leggere le email ricevute negli ultimi cinque giorni dai clienti enterprise, identificare quelle con una richiesta esplicita di follow-up, produrre una sintesi per priorità. Manus legge davvero la posta, applica i filtri, restituisce la sintesi. Con Slack attivo si può chiedere di guardare il canale vendite delle ultime due settimane e riassumere le obiezioni ricorrenti dalle call. A maggio 2026 Manus ha aggiunto i Connector Recommendations, che identificano quando un task richiede un servizio non ancora collegato e suggeriscono di attivarlo dall’interfaccia, riducendo l’attrito di scoprire a metà task che mancava una credenziale.
La tentazione iniziale è creare un Project generico chiamato “lavoro” e usarlo per tutto. Funziona male, e dopo qualche settimana produce confusione. La logica corretta è creare Project ristretti per dominio o per processo, uno per la competitive intelligence, uno per la produzione di contenuti, uno per l’analisi del customer feedback, ognuno con istruzioni mirate e connettori selezionati. Sui connettori conviene restare minimali, perché ogni connettore amplia la superficie di accesso ai dati: un Project di ricerca pubblica non ha bisogno di Gmail collegato, uno di produzione contenuti non ha bisogno di Stripe. La regola del privilegio minimo si applica anche qui, e protegge da scenari dove l’agente, in un momento di confusione, accede a dati che non doveva toccare.
Wide Research, la funzione dove Manus stacca gli altri
Ci sono task per cui un chatbot non basta, e per cui anche una “deep research” come quella di ChatGPT o Perplexity resta in superficie. Sono i dossier che richiedono di aprire decine di pagine, leggerle integralmente, estrarre dati strutturati, confrontarli, citarli con riferimenti puntuali. Wide Research è la funzione di Manus AI pensata esattamente per questo, disponibile sui piani Pro da quaranta dollari mensili in su, ed è uno dei punti dove il prodotto mostra il suo vantaggio competitivo più chiaro.
L’agente entra in una sessione estesa, lavora per quaranta-ottanta minuti, apre decine o centinaia di pagine, mantiene uno stato persistente, salva risultati intermedi, consegna un dossier corposo. La differenza con le ricerche standard riguarda la durata, certo, ma soprattutto la profondità di lettura: invece di fermarsi agli snippet dei primi risultati, l’agente apre davvero le pagine e le legge per intero. Sul confronto con la “deep research” di altri vale la pena guardare i numeri con cautela. Un’analisi su The Planet Tools che ha testato Manus su GAIA, il benchmark di riferimento per agenti AI, riporta uno score dell’86,5 per cento sul livello uno, 70,1 sul livello due, 57,7 sul livello tre, contro il 74,3, 69,1 e 47,6 di OpenAI Deep Research. I benchmark di prodotto vanno presi con le pinze, ma indicano una direzione: su task di ricerca multi-step strutturati Manus si comporta in modo competitivo, e in alcuni scenari supera la concorrenza più affermata.
Le regole sul brief valgono qui con un’intensità maggiore, perché un brief vago per un task da cinquanta crediti produce uno spreco accettabile, mentre per un task da cinquemila crediti produce uno spreco doloroso. I quattro elementi che fanno la differenza sono il perimetro, la struttura dell’output, le fonti accettabili, i criteri di successo. Wide Research rende particolarmente bene su tre terreni. La competitive intelligence strutturata, dove l’agente apre siti aziendali, comunicati, press release, e produce dossier che a un analista umano richiederebbero due o tre giornate. La due diligence light, che non sostituisce quella formale ma serve a valutare preliminarmente una controparte, raccogliendo informazioni pubbliche, segnalando red flag, ricostruendo la storia del management, con la capacità di citare puntualmente le fonti costruendo un audit trail della ricerca. Il market scan e la ricerca regolatoria, dove serve coprire molte fonti istituzionali, paper, comunicati di authority, banche centrali, organismi europei.
Sui costi conviene dare cifre concrete, perché il modello a crediti rende facile sottostimare l’investimento finché non ci si trova il budget mensile bruciato a metà mese. Un dossier di complessità media consuma tra i mille e i tremila crediti, uno ad alta complessità arriva a quattromila o diecimila in un’unica esecuzione. Sul piano Pro da quaranta dollari con ottomila crediti mensili, un task ben dimensionato occupa il dieci per cento del budget, mentre uno fuori scala può cannibalizzare un mese intero. Il calcolo che vale la pena fare è quanto tempo umano risparmia il dossier: se un’analisi da otto ore viene prodotta in trenta minuti con duemila crediti, il ROI è evidente, se invece il dossier è di qualità scarsa e va integrato a mano per quattro ore, il calcolo si ribalta. Per i dossier davvero importanti, quelli destinati a riunioni con stakeholder esterni o a decisioni di investimento, conviene un pilot in piccolo: stessa struttura ma su due o tre soggetti invece di dieci, si valuta la qualità, si calibra il brief, poi si lancia il task completo.
Wide Research è la scelta sbagliata quando la fonte primaria è una sola e già nota, e allora conviene caricare il documento in Chat Mode o in un Project e ragionarci sopra. Lo è quando la ricerca richiede accesso a database proprietari come Bloomberg, Crunchbase Pro, Pitchbook, perché Manus non ha accesso nativo e produrrà un dossier basato su fonti pubbliche più povere. E non funziona quando la domanda è soggettiva e richiede un giudizio interpretativo che presuppone esperienza di settore, perché valutare se un’azienda è un buon target di acquisizione è una sintesi di mercato, finanza, competitive e fit culturale che richiede chi conosce il contesto strategico interno. Wide Research prepara il terreno, non prende la decisione.
Scheduled Tasks e Cloud Computer: l’agente che lavora anche di notte
C’è un momento, in chi inizia a usare Manus seriamente, in cui ci si accorge che il vero collo di bottiglia si sposta: dalla capacità dell’agente al tempo dell’utente che deve lanciare i task. Le riunioni occupano la mattina, le revisioni il pomeriggio, e i task ricorrenti che si volevano lanciare ogni settimana si fanno una volta sì e due no, finché si smette. Qui Manus ha investito di più nell’ultimo anno, e a fine aprile 2026 ha consegnato il salto più rilevante del suo percorso prodotto.
Scheduled Tasks permette di programmare l’esecuzione di un task a cadenza fissa, ogni mattina, ogni lunedì, il primo del mese, ogni tre ore. L’agente lancia il task in autonomia, esegue, salva i risultati, eventualmente invia notifiche. Per chi è abituato a Zapier o n8n l’idea è familiare, per chi viene solo da chatbot è un cambio di prospettiva. Una review su Work Management lo descrive come la funzione che fa sembrare Manus più un operations tool che una novità AI, ed è fedele, perché il valore non sta nel singolo task pianificato ma nell’accumularsi di task ricorrenti che insieme costruiscono una piccola infrastruttura di business intelligence che gira da sola. I limiti vanno conosciuti: sul piano gratuito due Scheduled Tasks attivi, sui piani Pro il limite sale a venti task concorrenti e pianificati.
Il salto qualitativo è il Manus Cloud Computer, lanciato il 30 aprile 2026, descritto dalla stampa specializzata come il primo prodotto mainstream che dà a un agente un “permanent home”. Fino ad allora ogni sessione viveva in una sandbox effimera che si chiudeva al termine del task, mentre con Cloud Computer l’agente ha una macchina virtuale dedicata, sempre accesa, che mantiene stato, file, database, processi attivi anche tra un task e l’altro. Una rassegna su AI Automation Global descrive l’impatto come il passaggio dal 2025, anno del chat agent, al 2026, anno dell’agent runtime, un posto dove gli agenti vivono, reagiscono a eventi, accumulano effetti collaterali. Cloud Computer è disponibile in tre tier, accessibile da desktop e mobile, ed è proposto come no-code: si descrive l’obiettivo in linguaggio naturale e Manus provisiona e mantiene la macchina sottostante. Per le funzioni IT abituate a parlare di VM, container, processi supervisor, l’astrazione conta, perché non si gestisce più infrastruttura, si gestisce intento.
Gli scenari dove Scheduled Tasks ripaga rapidamente sono concreti. Il monitoring competitivo giornaliero, un task che ogni mattina controlla i siti dei competitor selezionati e invia un digest entro le otto, così il manager arriva in ufficio già allineato. Il digest settimanale di customer feedback, che ogni lunedì apre i ticket della settimana precedente, identifica i topic ricorrenti, segnala i feedback critici. La rassegna stampa di nicchia, che per chi lavora in public affairs o comunicazione scandaglia testate specializzate e account di settore producendo una rassegna ragionata, un sostituto credibile per certi scenari di servizi più costosi. Un caso descritto su NoCode MBA mostra come un setup simile per tracciare advertiser su newsletter di settore abbia intercettato lead prima della concorrenza.
I task pianificati hanno insidie diverse da quelli in tempo reale. Un task lanciato a mano lo supervisioni e se va male lo fermi, uno pianificato gira di notte e se sbaglia produce output sbagliati per giorni prima che qualcuno se ne accorga. Tre regole tengono conto di questa asimmetria. Essere conservativi sul perimetro, perché un task ricorrente deve fare poco ma bene, non è il contesto per un Wide Research da quattromila crediti ma per task semplici da cento o duecento. Configurare il fail-fast, in modo che se le fonti non sono accessibili l’agente notifichi l’errore invece di produrre output silenziosamente sbagliato. Fare una review periodica, una volta al mese, per vedere quali task generano valore e quali sono diventati rumore di fondo, perché la tendenza naturale è accumulare task senza mai potarli e dopo sei mesi ci si ritrova con quindici Scheduled Tasks di cui tre servono davvero.
Il valore vero emerge quando queste funzioni si combinano. Un Project con istruzioni mirate, connettori attivi sui propri tool, Scheduled Tasks che girano in autonomia, Cloud Computer che mantiene stato persistente, insieme diventano un’infrastruttura leggera di automazione che assomiglia a quello che le aziende grandi costruiscono con team IT dedicati. Un Project di sales intelligence con HubSpot attivo, dove ogni mattina un task apre i deal stagnanti da più di trenta giorni, controlla l’attività recente dei contatti su LinkedIn, identifica trigger di vita come un cambio ruolo o un post recente, suggerisce a quale account dare follow-up prioritario, con il Cloud Computer che mantiene memoria di lungo termine sui contatti per non ripetere segnalazioni già fatte. Due anni fa questo livello richiedeva un team di RevOps con Salesforce, Outreach, Clay, Apollo e un consulente di setup, oggi richiede un piano Manus Pro e una settimana di configurazione. C’è un caveat che ricordo sempre: tutta questa infrastruttura passa da una piattaforma esterna che ha accesso a dati aziendali sensibili, e il livello di automazione raggiunto è proporzionale alla quantità di credenziali condivise, un tema che chi ha vincoli di sovranità del dato risolve spostando lo strato AI dentro il perimetro, come racconto a proposito di infrastrutture di AI privata.
Collab, Desktop App e Design View: quando diventa risorsa di squadra
Per buona parte del 2025 Manus era un prodotto individuale. Un singolo utente apriva un task, lo seguiva, ne raccoglieva l’output, e per i team che volevano usarlo insieme l’unica strada era condividere screenshot e riprodurre a mano la stessa esecuzione. Da fine 2025 il prodotto ha coperto questo limite con un set di funzioni dedicate al lavoro di squadra.
Manus Collab apre i workspace alla collaborazione multi-utente con un solo link. Si genera, si condivide, e chi lo riceve entra nel workspace, vede lo stato dei task, partecipa alle conversazioni con l’agente, contribuisce al brief, accede agli output. Per chi viene da Notion, Linear, Figma, il pattern è familiare. L’effetto si misura sul sistemico più che sulla singola funzione: quando due persone lavorano insieme su un task le iterazioni si moltiplicano, una scrive il brief, l’altra lo affina, una valuta l’output intermedio, l’altra chiede correzioni, e la qualità finale supera quella che si otterrebbe in solitaria. Una review su Lindy nota che il lavoro di squadra è uno dei terreni dove i prodotti agentici stanno colmando il distacco rispetto agli strumenti collaborativi tradizionali. Un Manus solitario è uno strumento, un Manus condiviso può diventare un processo aziendale.
La Desktop App per Mac e Windows, descritta nella documentazione come “My Computer”, porta tre vantaggi pratici. L’accesso ai file locali senza upload manuale, così si lavora su documenti e fogli che vivono sulla propria macchina senza prima caricarli nel cloud. La persistenza visiva, perché l’app resta aperta in background e le notifiche sui task completati arrivano nel sistema operativo invece di disperdersi tra mille schede. E il senso di professionalità dello strumento, meno banale di quanto sembri, perché un’applicazione dedicata cambia il modo in cui un team percepisce un tool e abbassa la resistenza all’adozione strutturata. Resta una limitazione che conviene conoscere: anche con l’app desktop, l’esecuzione dell’agente avviene nella sandbox cloud, non sulla macchina locale, ed è un vincolo di sicurezza che vale per tutti gli agenti autonomi sul mercato.
Design View è il modulo dedicato alla generazione e all’editing di immagini, lanciato con una novità tecnica: integra Nano Banana Pro, il modello di generazione visuale di Google noto per la qualità delle iterazioni successive a partire dalla stessa immagine sorgente. Si carica o si genera un’immagine, e si chiedono modifiche in linguaggio naturale, cambia lo sfondo, togli la persona sulla destra, trasforma il giorno in notte, ogni modifica produce una nuova versione e il workspace mantiene la storia delle iterazioni. Per il marketing serve a produrre varianti per A/B test, social, landing page senza passare ogni volta dal design team per modifiche minori, per il design diventa uno sketchbook collaborativo, per la comunicazione interna permette di personalizzare template senza competenze grafiche. La qualità di Nano Banana Pro è alta sulle modifiche iterative dello stesso soggetto, meno costante quando si chiede una composizione completamente nuova, quindi conviene trattarlo come strumento di editing più che di creazione, affidando le brand asset di valore alto a designer professionisti.
C’è un tratto che accomuna gli scenari di squadra, e vale la pena fissarlo. Il valore di Manus per i team non sta nella sostituzione del lavoro umano, sta nella riduzione del tempo morto tra una decisione e la sua materializzazione. Cambia il throughput del processo creativo o produttivo, non la qualità finale dell’output, che resta dipendente dalla professionalità di chi lavora. Per aziende dove il time-to-market dei contenuti o delle materializzazioni visuali è un fattore competitivo, è una differenza che si misura in giornate di lavoro recuperate ogni settimana.

API e Custom MCP Server: integrare l’agente nei sistemi aziendali
C’è una fascia di lettori per cui usare Manus come prodotto finito non basta. Sono i CTO, gli IT manager, i lead developer che devono valutare se e come integrarlo dentro flussi esistenti, sopra database proprietari, dentro pipeline che girano su altri stack. Per questi profili la domanda non è come si usa Manus, è come si costruisce qualcosa con Manus. Due strade complementari, l’API per integrazioni server-to-server e i Custom MCP Server per esporre i sistemi interni all’agente.
L’API Manus permette a un sistema esterno di lanciare task sull’agente, ricevere risultati, gestire l’esecuzione in modo programmatico. La logica è quella di qualunque API moderna, chiave di accesso, endpoint, JSON in input e output, gestione asincrona dei task lunghi. Un caveat onesto: la documentazione tecnica sull’API è ancora in consolidamento e non ha la completezza di provider più maturi come OpenAI o Anthropic. Una guida su Skywork che ha analizzato pattern di integrazione con Stripe, Slack, Notion e Google Sheets nota che Manus si concentra sulla generazione rapida di app complete ma non documenta pubblicamente un developer SDK, un marketplace di plugin o un framework webhook strutturato. In pratica le integrazioni oggi si fanno in due modi, tramite middleware costruito ad hoc che riceve eventi dai propri sistemi e li traduce in chiamate Manus, oppure tramite polling per i servizi senza webhook affidabili. Entrambi richiedono uno sviluppatore esperto, e nessuno dei due è plug-and-play come l’esperienza dei Connectors nativi.
I Custom MCP Server fanno l’opposto: permettono a Manus di chiamare i sistemi aziendali interni come se fossero strumenti standard. Per le aziende strutturate è la direzione più potente, perché evita il problema della completezza dell’API e sfrutta lo standard aperto MCP. Si costruisce un server, ospitabile in cloud privato, on-premise o hybrid, che espone una serie di tool al protocollo, ognuno con un nome, una descrizione, parametri tipizzati, e un’implementazione che parla con i sistemi interni, per esempio “trova cliente per codice fiscale”, “estrai ultime fatture”, “aggiorna stato pratica”, “verifica disponibilità magazzino”. Si configura Manus per usare il server, e da quel momento l’agente opera sui sistemi proprietari dentro qualunque task autonomo. La documentazione integrazioni di Manus indica proprio questa possibilità di esporre CRM interni, database, API legacy in modo nativo. Per chi conosce il pattern del tool function calling negli LLM tradizionali, è la stessa cosa elevata a protocollo aperto e portabile, dove il server scritto per Manus può in linea di principio essere usato da altri agenti compatibili MCP, evitando il lock-in tecnologico.
Tre pattern ricorrono nelle integrazioni serie. Il ticket-enrichment, dove un sistema di ticketing genera un ticket, un trigger chiama Manus che con un Custom MCP Server sul CRM interno analizza il contenuto, identifica il cliente, recupera lo storico, classifica la richiesta, propone una priorità e un primo draft di risposta, e il ticket arricchito torna all’operatore umano con contesto già pronto. Il monitoring-and-routing, dove una pipeline di ingestion raccoglie input eterogenei e un task Manus li classifica, identifica i casi che richiedono attenzione umana, indirizza gli altri verso processi automatici, lo smistamento intelligente che dieci anni fa richiedeva regole if-then complesse. Il report-and-distribute, dove un task pianificato genera report periodici partendo da CRM, ERP, BI, li compone in documenti formattati, li distribuisce via email, Slack, Notion, una sostituzione credibile di parte del lavoro che oggi fanno manualmente i business analyst.
Tre temi tecnici vanno affrontati prima dello sviluppo. Webhook e polling sono i due modelli per la reattività, i webhook efficienti ma con endpoint pubblici e gestione delle retry, il polling più semplice ma con latenza e carico costante, e nella maggior parte dei casi conviene un layer ibrido. La gestione delle credenziali è il punto sensibile, perché con i Custom MCP Server le credenziali ai sistemi interni vivono nel server stesso, che diventa il punto critico di sicurezza, da isolare in rete dedicata, con credentials manager come Vault o i secrets manager cloud, con rotazione regolare e log di ogni accesso. L’idempotenza è il terzo, perché un task Manus può essere ritentato dopo errore o ricevere lo stesso input due volte, e i tool esposti devono produrre lo stesso risultato se chiamati due volte con gli stessi parametri, evitando doppie scritture. Sulla scelta tra costruire e comprare, il criterio è quello classico: si costruisce custom quando ci sono sistemi proprietari unici, requisiti di sicurezza specifici, volumi che ammortizzano lo sviluppo, e si compra il prodotto quando il caso d’uso è coperto dai Connectors nativi e il team non ha competenze per mantenere integrazioni custom. La variante intermedia più frequente è “buy the platform, build the connectors”, Manus come piattaforma chiavi in mano per il novanta per cento dei casi standard e un Custom MCP Server dedicato per i sistemi proprietari critici.
Adozione enterprise: governance, sicurezza, costi, proprietà
Un decisore che ha capito cosa fa il prodotto si trova davanti alle domande che contano quando si passa da “uno sperimenta nel team” a “lo adottiamo come strumento aziendale”. Quanto costa su scala team, quali garanzie di sicurezza offre, dove finiscono i dati, qual è il contesto di proprietà e governance, quando vale la pena e quando no.
Su scala team la logica di Manus AI è la stessa degli utenti individuali, con dinamiche di scala da comprendere. Il piano Team parte da venti dollari al mese per seat con un minimo di due membri, e introduce workspace condiviso, single sign-on, funzionalità di amministrazione, una pool di crediti gestita collettivamente. Per un’azienda con dieci utilizzatori attivi il costo base è duecento dollari al mese, più gli eventuali add-on per i picchi. Il calcolo che conta è quello dei crediti, non quello del seat, perché i casi più costosi, Wide Research, Cloud Computer attivo, task autonomi lunghi, concentrano buona parte del budget se non si stabilisce una disciplina interna. I crediti mensili non si accumulano, quelli da add-on restano finché l’abbonamento è attivo, e questa asimmetria spinge a una calibrazione fine, meglio un piano leggermente sotto il fabbisogno medio integrato con add-on quando serve, che un piano sovradimensionato che spreca crediti ogni mese.
Tre limiti operativi impattano l’organizzazione. Il limite di task concorrenti, uno solo sul gratuito, venti su Pro, scalabile con i seat ma con un tetto sul Team, che emerge quando un team di otto persone tenta di lanciare ognuno un Wide Research nello stesso pomeriggio e alcuni restano in coda. Il limite di Scheduled Tasks attivi, dove la disciplina di tenere pochi task ben fatti è anche un’auto-limitazione virtuosa. Il limite di Wide Research, dove le sessioni hanno durate massime e i crediti possono saturare il budget mensile, tanto che per team con bisogno frequente di dossier il piano top da duecento dollari diventa quello sostenibile.
Su sicurezza, data residency e audit trail Manus ha una maturità intermedia, i meccanismi di base ci sono ma la documentazione enterprise non è ancora al livello dei provider più consolidati. Tutto ciò che passa per la sandbox cloud, file caricati, contenuti delle conversazioni, output prodotti, viene processato dalla piattaforma, e per dati non particolarmente sensibili è coerente con qualunque SaaS moderno. Per dati regolamentati, categorie particolari GDPR, segreto bancario, dati sanitari, classificati pubblici, questa è la prima asimmetria da considerare, perché Manus non è oggi un prodotto certificato per la gestione di dati ad alta sensibilità, e per questi scenari va verificato puntualmente cosa il proprio framework di compliance consente. Sulla data residency, l’infrastruttura sottostante gira su provider cloud americani, e per aziende italiane ed europee in PA centrale o in settori finanziari di rilevanza sistemica, con vincoli espliciti di sovranità del dato, questo è un nodo da valutare caso per caso. Per la maggior parte delle aziende private il framework di trasferimento internazionale copre adeguatamente, ma l’analisi va documentata formalmente. Sull’audit trail il prodotto registra conversazioni ed esecuzioni e offre l’accesso alla cronologia, sufficiente per l’accountability interna, mentre per audit formali le funzionalità avanzate come log immutabili, export strutturato, integrazione SIEM, sono in consolidamento e vanno verificate con il vendor.
C’è poi un punto di proprietà e governance del prodotto che merita di essere riportato con precisione, perché si è mosso parecchio negli ultimi mesi. Manus nasce da Butterfly Effect, società fondata in Cina con radici a Pechino e Wuhan, poi reincorporata a Singapore nel 2025. A dicembre 2025 Meta ha annunciato l’acquisizione di Manus, riportata intorno ai due miliardi di dollari, dichiarando che avrebbe accelerato l’innovazione AI per i propri prodotti consumer ed enterprise. L’operazione ha attratto scrutinio sia negli Stati Uniti sia in Cina, e il 27 aprile 2026 la National Development and Reform Commission cinese ha bloccato l’acquisizione, chiedendo alle parti di annullarla, in una mossa che la stampa internazionale ha collegato alle preoccupazioni di Pechino sul trasferimento di tecnologia avanzata e talento. Meta ha risposto che la transazione era pienamente conforme alle leggi applicabili e che si attende una risoluzione appropriata della questione. Allo stato attuale lo scenario resta aperto e non del tutto chiarito, anche perché parte del personale risultava già integrato nei team Meta. Per le aziende che valutano l’adozione il punto non è prendere posizione su una vicenda geopolitica, è registrare che il prodotto attraversa una fase di evoluzione e incertezza societaria, con i lati positivi degli investimenti continui e i lati di consapevolezza sui possibili cambiamenti di pricing e di policy. Per settori con vincoli stringenti sulla provenienza geografica dei fornitori cloud, PA centrale, difesa, sanità, banking sistemico, questo va verificato con le funzioni di compliance interne, mentre per il resto del mercato privato il tema è meno stringente di quanto a volte appaia.
La griglia decisionale: quando Manus AI è la scelta giusta
Resta da mettere insieme tutto in criteri sintetici, da combinare con il contesto specifico di ogni azienda. La domanda preliminare, prima ancora di aprire l’account, riguarda il proprio flusso di lavoro: ha task multi-passo che oggi vengono eseguiti a mano per mancanza di alternative, oppure è già strutturato intorno a strumenti specializzati che coprono ogni segmento?
Una griglia grossolana ma utile parte dal tempo. Se il task richiede meno di cinque minuti di lavoro umano, Manus è un’overkill costosa ed è meglio un assistente conversazionale. Se richiede tra cinque minuti e un’ora, e attraversa più strumenti o più fonti, Manus può essere la scelta giusta. Se richiede più di un’ora di lavoro complesso ma altamente strutturato, vale la pena valutare se non sia più adatto a una pipeline costruita con API e tooling dedicato. Manus è la scelta giusta quando l’azienda ha bisogno regolare di task multi-passo oggi eseguiti a mano, quando il team ha competenze digitali medio-alte e può investire un mese o due nella curva di apprendimento, quando i casi d’uso prevalenti riguardano ricerca approfondita, generazione di documenti formattati, monitoraggio continuo, supporto a customer operations e sales, e quando i dati toccati non sono in fasce di sensibilità elevata oppure si è disposti a costruire un Custom MCP Server che isoli il perimetro.
È invece da rivalutare con attenzione quando l’azienda opera in settori altamente regolati con vincoli di sovranità del dato espliciti, quando il team non ha la disponibilità per investire nella curva di apprendimento e cerca un tool da accendere e usare, quando i casi d’uso sono prevalentemente conversazionali e iterativi, per i quali un assistente tradizionale è più adatto, e quando il budget è strutturalmente sotto i venti dollari mensili per utente, perché il modello a crediti rende il piano gratuito limitante per un uso professionale serio.
In molti casi reali la risposta sta nel mezzo, ed è una valutazione sfumata che conviene chiudere con un pilot strutturato, un trimestre di prova con un team ristretto di tre o cinque power user, obiettivi misurabili sul tempo umano risparmiato e sulla qualità degli output, e una decisione formale a fine trimestre se estendere all’organizzazione o fermarsi. È l’approccio che evita sia il rifiuto pregiudiziale sia l’adesione entusiastica non sostenibile, ed è quello che la maggior parte delle aziende che adottano con successo nuovi tool AI sta usando in questa fase. C’è anche un criterio organizzativo che vedo spesso sottovalutato: le aziende che adottano Manus con successo sono quelle che dedicano una persona o un piccolo team alla curva di apprendimento iniziale, prima di estendere l’uso al resto dell’organizzazione, perché lanciarlo dall’alto come tool generalista, senza un nucleo di power user che sviluppi pattern riconoscibili, tende a produrre frustrazione e abbandono.
Tutto questo ragionamento, dalla scelta del modello fino all’architettura di governance, è esattamente il tipo di valutazione che mi capita di affiancare quando un’azienda mi chiede un assessment sulla propria adozione AI. Se Manus entra in un disegno più ampio di sovranità del dato e infrastruttura interna, vale la pena leggerlo insieme alle scelte di stack che ho raccontato altrove, dal perché Mistral è diventata la scelta enterprise più seria d’Europa per chi vuole l’AI dentro il proprio perimetro, fino a cosa cambia per il GDPR quando un dato esce dall’azienda e si appoggia a una piattaforma esterna come Manus. In Pelle Digitale ho provato a descrivere come l’interfaccia digitale media il nostro rapporto con il lavoro e con noi stessi, e un agente autonomo come Manus è il caso limite di questa mediazione, uno strumento che non risponde più soltanto, agisce. Per una conversazione diretta sul vostro caso specifico c’è la pagina Advisory.
A inizio percorso lasciavo aperta una domanda, e la richiudo qui dopo aver attraversato tutto il prodotto. Aprire un account, dedicare due settimane all’esperimento concreto, scegliere tre task realistici del proprio lavoro e provarli con la disciplina vista in queste pagine, perché la risposta sul valore di Manus per il proprio contesto arriva solo dall’esperienza diretta e nessuna guida può sostituirla. Senza dubbio è in quella prova concreta che si gioca la differenza tra chi avrà cavalcato l’onda degli agenti autonomi e chi la guarderà passare?