Sovranità dell’AI: quando un governo può spegnere un modello
Venerdì 12 giugno 2026, ore 17:21 a New York. Anthropic riceve una lettera dal governo degli Stati Uniti e nel giro di poche ore disattiva i suoi due modelli più potenti, Fable 5 e Mythos 5, per l’intera base clienti, ovunque nel mondo. La motivazione, dichiarata nel comunicato ufficiale dell’azienda, è un export control per ragioni di sicurezza nazionale che vieta l’accesso a qualunque cittadino straniero, dentro e fuori dagli Stati Uniti, compresi i dipendenti stranieri della stessa Anthropic.
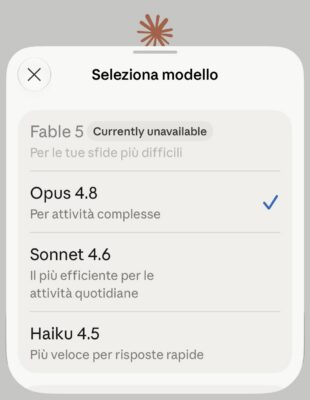
Non discuto qui chi abbia ragione. Mi interessa una cosa più semplice, e più scomoda, che fino a quella sera in molti trattavano come un dettaglio tecnico: l’accesso ai modelli di frontiera è un permesso, e un permesso lo concede qualcuno che può anche ritirarlo.
Un export control ha messo offline un modello di frontiera
La direttiva è arrivata venerdì pomeriggio, alle 17:21 ora della costa Est. Secondo NBC News a firmarla è stato il Segretario al Commercio Howard Lutnick, con i funzionari del Bureau of Industry and Security, l’ufficio che negli Stati Uniti gestisce le restrizioni all’export. È lo stesso strumento con cui negli anni Novanta Washington trattava la crittografia come un’arma da guerra, soggetta alle regole sull’export militare. Anthropic ha scelto di spegnere i modelli per tutti, perché applicare il divieto ai soli stranieri avrebbe comunque tagliato fuori una parte enorme di utenti, inclusi i suoi stessi dipendenti non statunitensi.
L’azienda si adegua, ma dichiara di non essere d’accordo. Sostiene che la vulnerabilità contestata sia minore, che la prova ricevuta sia finora soltanto verbale, e che la stessa capacità sia già reperibile in altri modelli pubblici, incluso GPT-5.5 di OpenAI, e usata ogni giorno da chi i sistemi li difende. È, per quanto se ne sa, la prima volta che un’azienda AI di primo piano mette offline un modello già distribuito al pubblico per effetto di un intervento federale.
Il contesto pesa più della singola lettera. A febbraio l’amministrazione aveva provato a escludere i prodotti Anthropic dalle agenzie federali, l’azienda aveva fatto causa e un giudice le aveva dato ragione. La settimana scorsa è emerso che la National Security Agency stava usando Mythos per operazioni cyber offensive. E il 2 giugno è stato firmato un ordine esecutivo sull’AI che, tra le altre cose, prevede un meccanismo per dare al governo accesso anticipato, su base volontaria, ai modelli più potenti. Lo stesso modello che lo Stato vuole usare per la propria sicurezza è anche quello che lo Stato può decidere di spegnere, per la stessa ragione.
Permesso, non proprietà
Quando paghi l’abbonamento a un modello hai l’impressione di possederne l’uso. L’accesso non è un bene che possiedi, è un permesso che ti concedono, condizionato, che vive su infrastruttura di qualcun altro e sotto la legge di qualcun altro.
In Pelle Digitale ho provato a raccontare come il digitale sia diventato una seconda pelle, qualcosa che indossiamo senza più accorgercene finché funziona. La dipendenza più profonda è quella invisibile. La vedi solo il giorno in cui qualcuno la stacca, e venerdì centinaia di milioni di persone hanno visto la propria.
Il controllo dell’AI è verticale
Girano decine di schemi dello stack dell’AI. Alcuni lo disegnano come un mercato, con applicazioni e modelli e dati e infrastruttura, altri come un’architettura tecnica a livelli, altri ancora come una pila di governance che sale dalla sicurezza fino al consiglio di amministrazione. Linguaggi diversi per lo stesso oggetto.
Quasi nessuno mette in evidenza la dimensione che venerdì è diventata lampante. Il controllo è verticale. C’è una pila che parte dal silicio e arriva alla governance, con in mezzo il cloud, i pesi del modello, il runtime di inferenza, l’orchestrazione, le applicazioni. Puoi avere model card, audit trail e comitati etici impeccabili in cima, e perdere comunque l’accesso al modello perché una lettera, in un’altra capitale, ha deciso così. Una policy perfetta vale poco se il fondo della pila vive sotto la giurisdizione di un altro Stato.
Dove può intervenire davvero un’azienda privata?
Qui la domanda si fa concreta, e la risposta cambia da livello a livello.
Sul silicio un’azienda privata non interviene. Non progetta i chip, non controlla i grandi produttori, e l’export sui semiconduttori è una leva che si muove tra governi. È il piano geopolitico del controllo, quello su cui un’impresa, per quanto grande, resta sostanzialmente spettatrice.
Dal cloud in su la situazione si ribalta. L’infrastruttura puoi sceglierla, on-premise oppure su un cloud sovrano in giurisdizione europea. Il runtime di inferenza gira su software aperto, dentro il tuo perimetro. Per orchestrazione e agenti esistono standard aperti come MCP. Le applicazioni le disegni o le ospiti tu, e la governance, in cima, è per definizione tua.
In mezzo c’è il livello che decide tutto, il modello e i suoi pesi. Con pesi aperti, scaricati e ospitati sulla tua infrastruttura, il modello è tuo e nessuno te lo spegne da remoto. Con un’API proprietaria, per quanto eccellente, dipendi dalla continuità di servizio di chi te la fornisce, ed è esattamente lì che venerdì è caduta la direttiva.
Controllare l’intera pila, dal chip all’applicazione, è impraticabile per quasi qualunque organizzazione, e costoso anche solo provarci. La scelta sensata non sta nel possedere tutto, ma nel decidere, livello per livello, cosa tenere dentro il perimetro e cosa affittare sapendo bene che cosa si sta affittando.
Il metodo viene prima della tecnologia
Decidere quali livelli controllare è prima di tutto un esercizio di metodo: mappare le dipendenze reali, valutare la maturità dell’organizzazione, architettare quali strati portare in casa e con quale priorità, mettere governance e conformità, con l’AI Act in testa, dentro il progetto dall’inizio e non come timbro finale. È il lavoro che con ZeroFive provo a fare con un framework a cinque fasi, che parte dall’allineamento strategico e dalla valutazione della maturità, passa per l’architettura delle priorità e l’attivazione della governance, e arriva alla misurazione del valore nel tempo, con un’idea fissa, portare metodo dove l’industria porta hype.
Il metodo dice quali livelli pesano per te. Poi serve la tecnologia per tenerli davvero in mano, e sul livello che fa da bivio, il modello e il runtime, la risposta tecnica ha un nome preciso, l’open source. LocalAI è un motore di inferenza aperto, compatibile con le API di OpenAI e indipendente dal modello, pensato per far girare modelli a pesi aperti dentro il perimetro dell’azienda, senza che il dato esca e senza che l’accesso dipenda da una decisione presa da un’altra parte. È il progetto su cui lavoro, e lo cito per quello che è in questo discorso, un modo concreto per riportare il modello dalla parte di chi lo usa. Vale anche per chi si occupa di AI generativa in azienda: la scelta della pila viene prima della scelta del fornitore.
La direttiva del 12 giugno rientrerà quasi certamente, Anthropic stessa la legge come un malinteso, e l’accesso a Fable e Mythos tornerà. La lezione però resta anche dopo. Per chi costruisce in Europa la prossima domanda da portare in consiglio di amministrazione non riguarda quale modello sia il più bravo, ma quanta parte del proprio stack continuerebbe a funzionare il mattino dopo una lettera. Voi quanta parte ne avete?
Fonte primaria: Statement on the US government directive to suspend access to Fable 5 and Mythos 5, Anthropic, 12 giugno 2026. Ricostruzione del meccanismo governativo: NBC News. Contesto regolatorio: ordine esecutivo del 2 giugno 2026.