World model & LeCun: il nuovo strato dove l’intelligenza incontra il mondo
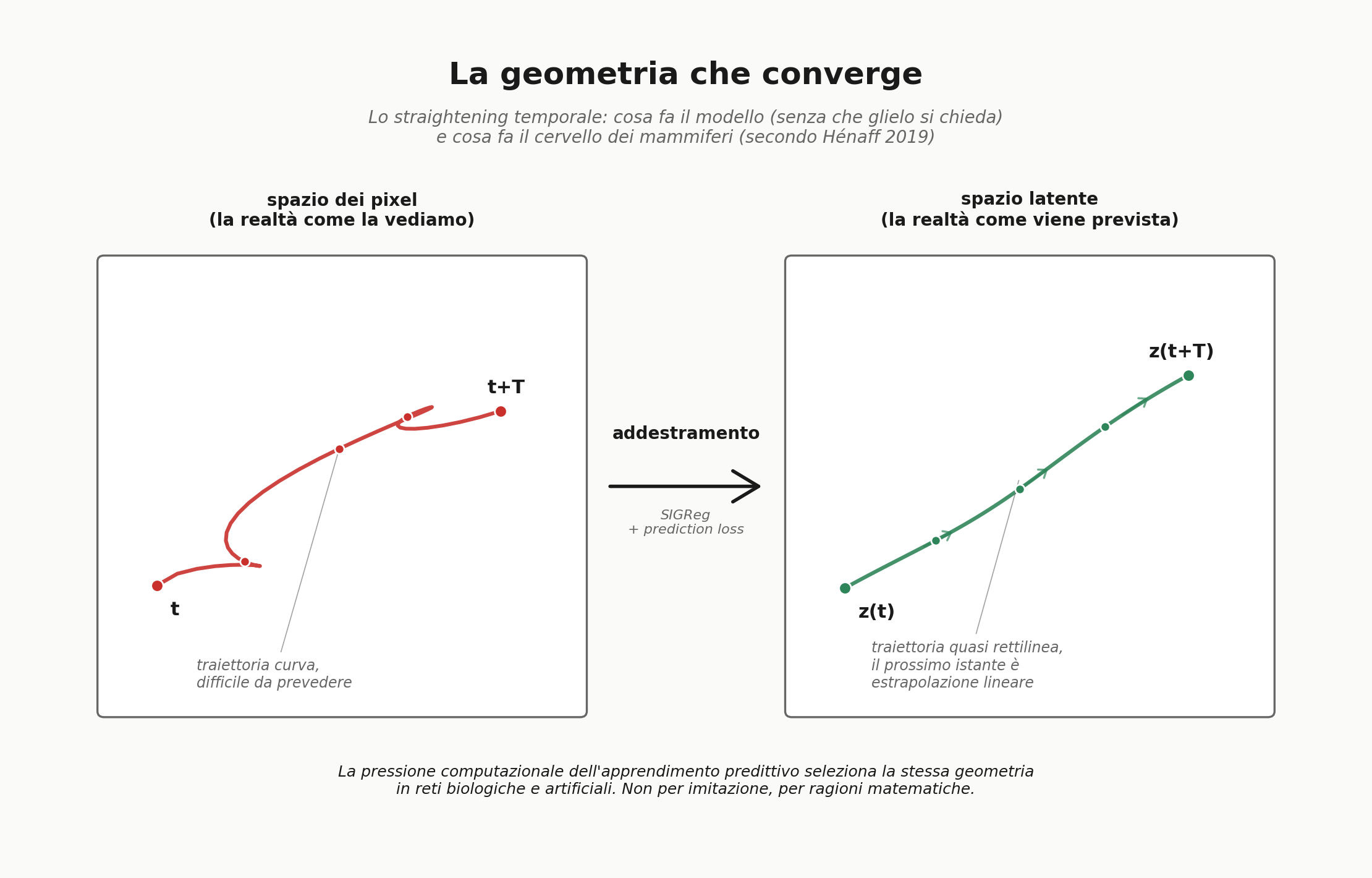
In alcuni casi, un grafico, nell’appendice di un paper appena uscito, dice più di tutto il paper se lo guardi con attenzione. È un grafico semplice. Mostra come, nel corso dell’addestramento di una rete neurale che impara a prevedere il futuro a partire da pixel grezzi, le traiettorie nello spazio interno del modello si “raddrizzino” progressivamente. Iniziano curve e complicate come la realtà che descrivono, e finiscono quasi rettilinee. Nessuno ha detto al modello di farlo, nessuna funzione di perdita lo chiede esplicitamente. Eppure il modello, lasciato libero di scoprire una rappresentazione utile per prevedere, sceglie la stessa cosa che il cervello dei mammiferi fa quando guarda un video, secondo l’ipotesi del “perceptual straightening” di Olivier Hénaff e colleghi: linearizzare il tempo, in modo che il prossimo istante sia letteralmente una linea retta a partire dall’istante presente.
Quel grafico non sembra molto. Eppure è una piccola crepa attraverso cui si vede una cosa più grande. L’idea che esista una geometria naturale dell’esperienza, una forma “giusta” in cui collassare il mondo per poterlo prevedere, e che reti artificiali e cervelli biologici, partendo da approcci radicalmente diversi, vi convergano. Il paper si chiama LeWorldModel, ed è firmato da Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun e Randall Balestriero. Tecnicamente è un risultato di ingegneria stupefacente: un modello di 15 milioni di parametri, addestrabile su una sola GPU in poche ore, che impara la fisica intuitiva di ambienti simulati direttamente da pixel grezzi, senza supervisione, senza ricompense, senza encoder pre-addestrati. Pianifica in meno di un secondo dove i suoi predecessori impiegavano 47.
Ma ciò che il paper dice esplicitamente è solo la prima metà della storia. La seconda, quella più interessante, è in ciò che mostra senza dichiararlo, e in dove ci sta portando questa direzione di ricerca quando la guardiamo con occhi che non sono quelli della sola comunità tecnica.
Quando una GPU basta a fare ricerca di frontiera
Per anni la narrazione dominante è stata che l’intelligenza artificiale di frontiera richieda scale crescenti di calcolo e di capitale, oltre a un consumo energetico in continua espansione. Chi non possiede datacenter da gigawatt resta a guardare. Una scuola di pensiero, fatta di realismo industriale, sosteneva che l’AGI sarebbe arrivata dal lato del molto grande. Un’altra, meno udibile nel rumore di fondo, sosteneva che il problema centrale non era la scala ma la struttura, e che modelli architetturalmente meglio pensati avrebbero potuto raggiungere capacità importanti con risorse modeste.
LeWorldModel è uno dei segnali che la seconda scuola comincia a portare risultati concreti. Quindici milioni di parametri sono cinque ordini di grandezza in meno rispetto ai modelli linguistici di frontiera. Una singola GPU L40S costa qualche migliaio di euro, è alla portata di un piccolo laboratorio universitario, di un team di ricerca indipendente, persino di un appassionato motivato. E con quella GPU, in poche ore, si addestra un modello che pianifica azioni di un braccio robotico con successo nel 96% dei casi. Non è poco, e non è solo una curiosità accademica.
Vale la pena soffermarsi su una conseguenza epistemica meno ovvia. Quando la ricerca di frontiera in un dominio diventa accessibile a chi non controlla infrastrutture colossali, la composizione di chi può contribuire cambia. Le università tornano in gioco. Le startup possono permettersi di partire dalla ricerca, non solo dal product-market fit. I ricercatori indipendenti possono replicare e modificare gli esperimenti, e da lì migliorarli. È successo nei primi anni del deep learning, prima che il costo del training delle reti di scala salissi al cielo. È successo nel software open source. Ed è il presupposto perché una tecnologia entri davvero nella cultura, anziché restare proprietà di pochi soggetti dotati di risorse fuori scala.
L’efficienza non è solo un dato di prestazione, ha conseguenze politiche. Decide chi può pensare la prossima generazione di una tecnologia. Il fatto che LeCun e il suo team abbiano deliberatamente progettato un modello “fattibile su una GPU sola”, e abbiano rilasciato codice e pesi su GitHub, dice qualcosa sulla scuola di pensiero da cui questo lavoro proviene. Non parliamo di ricerca da torre d’avorio, parliamo di ricerca pensata per essere distribuita.
Cosa significa “non collassare”, filosoficamente
Il problema centrale che il paper risolve si chiama “rappresentazione collassata”. Quando una rete neurale impara a prevedere il futuro da una rappresentazione compatta di sé stessa, c’è una scorciatoia che la tenta sempre: mappare tutti gli input sullo stesso vettore costante. In quel modo la previsione è banalmente corretta, perché tutto è uguale a tutto. Il modello tecnicamente funziona, ma ha smesso di codificare informazione. Ha trovato il punto di equilibrio termodinamico minimo della propria esistenza percettiva: non distinguere più nulla.
In questo fenomeno c’è qualcosa di filosoficamente inquietante, perché ricorda da vicino certe deformazioni dell’esperienza umana. La depressione clinica è stata descritta da alcuni neuroscienziati cognitivi come uno stato in cui le rappresentazioni interne smettono di differenziarsi: tutto sembra uguale, tutto perde salienza, il futuro coincide con il presente perché niente più cambia. La routine eccessiva, l’iper-prevedibilità degli ambienti digitali algoritmicamente personalizzati, una certa apatia che attraversa epoche di sovrabbondanza informativa: sono tutte forme di “collasso rappresentazionale” della coscienza umana, viste da questa angolazione.
La soluzione che LeWorldModel propone è semplice e bellissima. Si chiama SIGReg, e in sostanza forza le rappresentazioni interne del modello a distribuirsi come una gaussiana isotropa nello spazio latente, ovvero a occupare lo spazio in modo “ben formato”, senza concentrarsi in un punto, senza appiattirsi su una direzione. Matematicamente garantisce che il collasso sia impossibile, perché un vettore costante non può essere una distribuzione gaussiana. Filosoficamente è qualcosa di più: è l’imposizione di una varietà strutturale come condizione di possibilità della percezione. Vedere è anche distinguere, distinguere richiede di occupare lo spazio delle differenze in modo articolato. Una mente che non differenzia non vede.
Si sente un’eco interessante con il modo in cui pensiamo la salute cognitiva umana. Le esperienze che ci tengono “rappresentazionalmente vivi” sono quelle che ci espongono a varietà non triviale: viaggi reali (non turismo da fotocopia), conversazioni con persone diverse da noi, lavoro su problemi nuovi, contatto con realtà materiali che non possiamo prevedere. Quando ci appiattiamo su routine senza variazione, quando lasciamo che algoritmi ci servano sempre lo stesso tipo di contenuto, stiamo addestrando noi stessi al collasso. Una macchina ha bisogno di SIGReg per restare percettivamente viva. A noi serve qualcosa di analogo, e probabilmente passa anche dalle cose vecchio stile: leggere libri non scelti dall’algoritmo, fare conversazioni faccia a faccia, riappropriarsi del proprio corpo come strumento di esplorazione del mondo.
Le traiettorie che si raddrizzano da sole
Torniamo al grafico dell’appendice, quello che mi è rimasto in testa. Lo straightening temporale: il fenomeno per cui, durante l’addestramento, le traiettorie del modello nello spazio latente diventano sempre più rettilinee. È stato descritto nel 2019 da Hénaff e colleghi come ipotesi su come il sistema visivo dei mammiferi rappresenti il tempo: invece di mantenere la complessità geometrica del flusso ottico, il cervello “raddrizzerebbe” le traiettorie nello spazio neurale, rendendo la prossima posizione una semplice estrapolazione lineare di quella corrente.
Quello che gli autori di LeWorldModel hanno osservato è che il loro modello fa esattamente la stessa cosa, in modo emergente. Nessuna funzione di perdita lo richiede. Nessun termine di regolarizzazione lo premia. Eppure, mentre il modello impara a prevedere il prossimo embedding a partire dall’embedding corrente e dall’azione, la sua geometria interna si raddrizza spontaneamente. È come se la rete avesse “capito” che la cosa più semplice da prevedere è una linea retta, e abbia riorganizzato il proprio mondo interiore di conseguenza.
Questa convergenza tra biologico e artificiale è profondamente non banale. Significa che esiste una pressione strutturale dentro l’apprendimento predittivo, indipendente dal substrato biologico o artificiale, che spinge le rappresentazioni a organizzarsi in forme geometriche specifiche. Non è solo “il cervello e la rete neurale fanno la stessa cosa”. È più forte: è “la previsione del futuro, come compito formale, ha una geometria preferita”. Reti biologiche e artificiali la scoprono per ragioni computazionali, non per imitazione reciproca.
Se è vero, e per ora abbiamo indizi forti più che prove definitive, allora la convergenza tra intelligenze biologiche e artificiali potrebbe essere meno questione di “ingegnerizzare la biologia” e più questione di “lasciare che le strutture computazionali ottimali emergano da sole”. Le reti artificiali ben progettate, sottoposte a compiti analoghi a quelli che il cervello affronta, tenderanno a riscoprire le stesse soluzioni. Non perché copino, ma perché la matematica del problema le incanala lì.
Questa è un’ipotesi che cambia il modo in cui ragiono sulla questione “macchine come noi”. L’allineamento profondo tra AI e cognizione umana potrebbe non essere il risultato di uno sforzo deliberato di antropomorfizzare le reti, ma un attrattore naturale verso cui sistemi predittivi efficienti convergono, qualunque sia il loro substrato. Sarebbe una buona notizia per la sicurezza, una pessima notizia per chi pensava che il digitale potesse evolvere in qualcosa di radicalmente alieno. La nostra intelligenza e quella delle macchine vivono nello stesso paesaggio geometrico, perché il paesaggio lo definisce il compito, non il substrato.
Una geometria naturale per le rappresentazioni
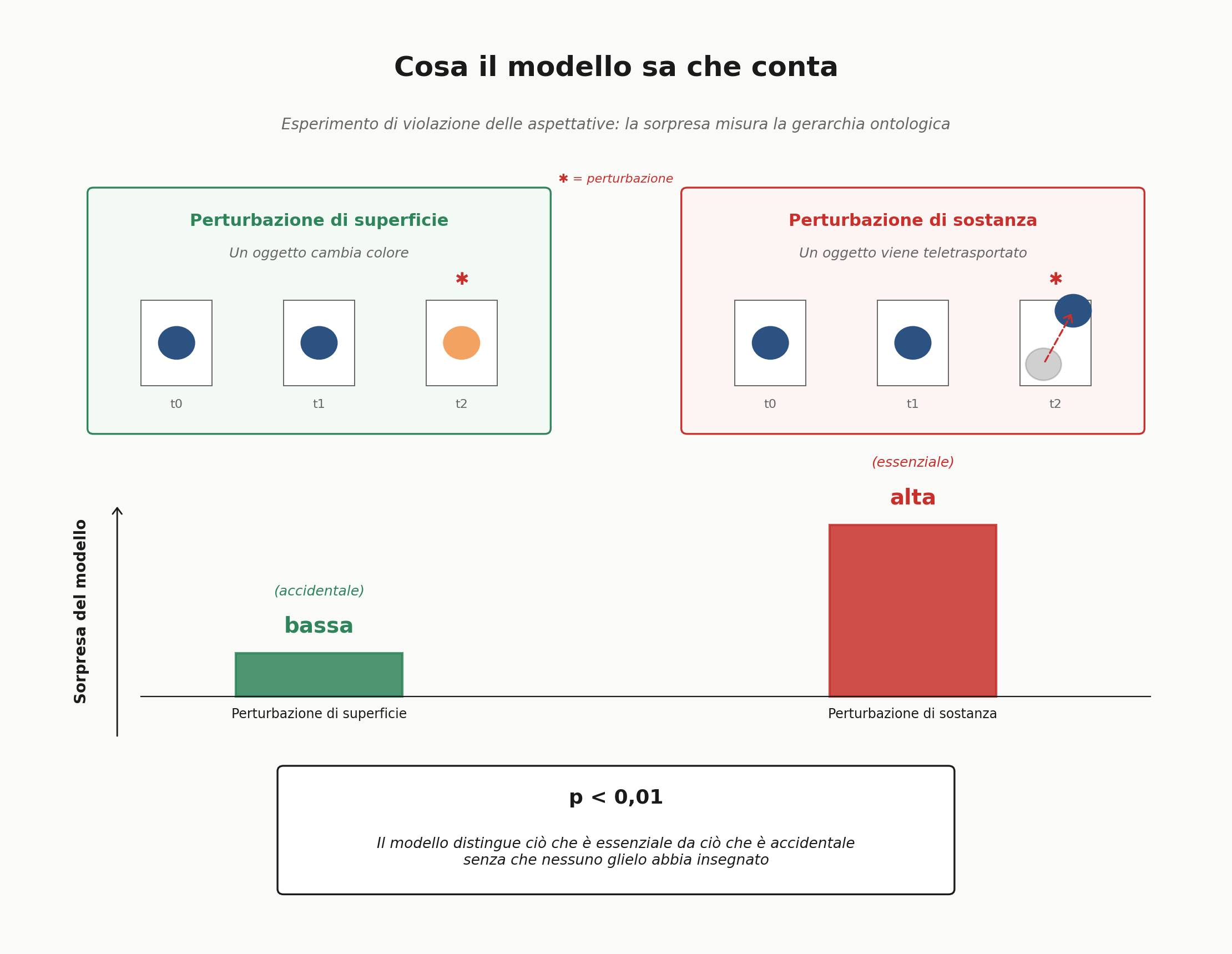
Il paper mostra senza enfatizzarla un’altra cosa che vale la pena tirare fuori. Quando il modello viene sottoposto a perturbazioni durante un episodio, gli autori distinguono due tipi: perturbazioni visive (un oggetto cambia colore di colpo) e perturbazioni fisiche (un oggetto viene teletrasportato in una posizione casuale, violando la continuità). Misurano poi la “sorpresa” del modello, ovvero quanto la sua previsione si discosta dall’osservazione reale, e confrontano le due condizioni.
Il risultato è che il modello reagisce poco al cambio di colore e tantissimo al teletrasporto. Statisticamente significativo, p minore di 0,01 sulla differenza tra le due condizioni. È un dato apparentemente piccolo, ma porta un’informazione enorme: il sistema ha sviluppato una gerarchia ontologica, sa che cambiare colore a un oggetto è un evento di superficie, mentre violare la continuità spaziale è un evento di sostanza. Il modello distingue la sostanza dall’apparenza senza che nessuno glielo abbia insegnato.
È una distinzione che la filosofia occidentale dibatte da Aristotele in poi: la domanda su quali proprietà di un oggetto siano essenziali e quali accidentali, su cosa faccia di una cosa “quella cosa” e non un’altra. La risposta che oggi arriva dalle reti predittive sembra essere questa: ciò che, se cambiato, rompe la previsione del futuro è essenziale, ciò che può cambiare senza disturbare la dinamica è accidentale. È una risposta funzionale, non metafisica, e proprio per questo è interessante. Risuona con certe intuizioni della fenomenologia: la sostanza di un oggetto è il suo modo di stare nelle nostre attese di esperienza, non una qualità nascosta dietro l’apparenza.
La macchina che impara a prevedere il futuro impara, lungo la strada, anche una forma rudimentale di ontologia. Sa cosa “conta” e cosa “non conta”. È capace di sorpresa selettiva, ovvero di sorprendersi solo quando vale la pena sorprendersi. Questo, in psicologia cognitiva, è la base dell’attenzione e della memoria semantica: non possiamo ricordare tutto, dobbiamo decidere cosa è rilevante, e la rilevanza emerge dalla struttura predittiva delle aspettative. Una macchina che ha imparato a sorprendersi solo per le perturbazioni fisiche ha imparato un proto-cogito.
Il modello che distingue la sostanza dall’apparenza
Una seconda osservazione, che il paper fa quasi en passant, merita di essere tirata fuori. Nell’ambiente OGBench-Cube, una scena 3D in cui un braccio robotico manipola un cubo, il modello riesce a prevedere bene la posizione del cubo e dell’end-effector, ma fa più fatica con l’orientamento rotazionale del braccio. In termini quantitativi, le metriche di probing sulle posizioni traslazionali sono ottime, quelle sulle rotazioni del polso del robot peggiorano sensibilmente.
L’indicazione è che il modello, nel comprimere il mondo in 192 dimensioni di spazio latente, ha dovuto scegliere cosa preservare e cosa lasciare cadere. Ha scelto di tenere le posizioni, perché sono più rilevanti per prevedere conseguenze (dove finirà il cubo è quasi tutto), e ha sacrificato i dettagli rotazionali fini. Parliamo di selezione percettiva, più che di limitazione tecnica. Il modello sviluppa una forma di attenzione strutturale: privilegia ciò che è macroscopicamente rilevante e ignora ciò che è microscopico, persino quando entrambi sono visibili nei dati di training.
Questo solleva una domanda interessante per chi si occupa di interfacce e sistemi cognitivi. Quanto della nostra esperienza visiva quotidiana è effettivamente codificato nel nostro spazio latente cerebrale, e quanto invece viene scartato perché non utile alla previsione? Le neuroscienze cognitive lo sanno da anni: la nostra visione è molto meno completa di quanto crediamo, il cervello ricostruisce e inferisce in continuazione, scartando i dettagli che non servono. La fovea vede ad alta risoluzione un’area minuscola, il resto è completamento. Eppure soggettivamente ci sembra di vedere tutto.
LeWorldModel, in piccolo, ci fa toccare con mano lo stesso fenomeno. Una mente predittiva, biologica o artificiale, comprime per essere efficiente, e nella compressione decide cosa fa parte della “realtà rappresentata” e cosa è rumore. La realtà smette di essere una proprietà oggettiva del mondo, diventa il sottoinsieme di esso che vale la pena prevedere. Questa è una conclusione filosofica antica, che torna oggi sotto forma di una proprietà misurabile di una rete neurale di 15 milioni di parametri.
L’intelligenza che torna nel corpo
Per quasi tutto il primo cinquantennio dell’intelligenza artificiale, la parte “intelligente” si è creduto fosse quella simbolica: ragionare in modo astratto e manipolare concetti, pianificare sequenze di passi mentali. Il corpo, la capacità di muoversi e di percepire, era considerato periferia. Negli ultimi quindici anni il deep learning ha rotto questo paradigma per quanto riguarda la percezione, ma ha lasciato il corpo fuori. I grandi modelli linguistici sono potenti elaboratori simbolici disincarnati, leggono il mondo solo attraverso il filtro dello scritto.
I world model latenti riportano l’AI dentro il mondo fisico. Non lo fanno generando immagini fotorealistiche del futuro, lo fanno costruendo rappresentazioni interne sufficienti a prevedere conseguenze. La differenza è enorme. Un’AI che genera mondi tridimensionali fotorealistici è uno strumento creativo straordinario, ma resta uno spettatore. Un’AI che ha un world model latente è qualcosa di diverso: ha un’idea operativa di come funziona il mondo, può usare quell’idea per agire, e l’agire la mette alla prova continuamente.
Questa transizione, dal mondo come testo al mondo come scena, è il cambiamento più importante che sta avvenendo in questi mesi nell’AI applicata, e probabilmente non sarà raccontato sui giornali per anni. Quando arriveranno i prodotti, ce ne accorgeremo. Saranno robot domestici che ragionano sulle conseguenze prima di agire, droni di consegna che pianificano traiettorie tenendo conto di vento e ostacoli mobili, sistemi di assistenza chirurgica che prevedono come reagirà un tessuto a una pressione. Ognuna di queste applicazioni richiede esattamente quel tipo di intelligenza che LeWorldModel comincia a dimostrare: leggera nel calcolo ma plausibilmente fisica nelle sue previsioni.
Una conseguenza tocca da vicino chi pensa il futuro del lavoro umano. Per un po’ abbiamo creduto che l’AI avrebbe sostituito prima i lavori manuali ripetitivi e poi quelli intellettuali. Si sta vedendo che è successo l’opposto: i mestieri intellettuali ripetitivi sono i primi a essere automatizzati dai LLM, mentre quelli manuali che richiedono comprensione fisica del mondo restano stabilmente umani perché manca la tecnologia di base. I world model sono il pezzo mancante che finalmente comincia ad arrivare. Quando saranno maturi, anche la frontiera del manuale si sposterà. Il valore umano si redistribuirà ancora, e non necessariamente verso ciò che ora pensiamo sia “al sicuro”.
La cosa interessante è che questa transizione non disumanizza, anzi. Riconcilia l’intelligenza con il corpo, dopo decenni di disembodiment cognitivo. Le macchine diventano più simili a noi proprio nel loro modo di abitare il mondo, e questo, almeno per come la vedo, è una buona notizia. Una macchina che capisce la gravità è una macchina con cui possiamo collaborare in modo più trasparente. Una macchina che è solo un grafo simbolico fluttuante nel cloud è opaca per definizione.
Il limite che racconta più del successo
Un risultato del paper, a prima vista, sembra un’imperfezione, e invece secondo me racconta una verità importante. Nell’ambiente Two-Room, il più semplice tra quelli testati, LeWorldModel funziona peggio dei suoi concorrenti. Un agente deve muoversi tra due stanze attraverso una porta, è un problema di navigazione 2D banale. Eppure il modello, che batte tutti nei compiti più complessi, qui perde terreno. Perché?
Gli autori avanzano un’ipotesi che vale la pena prendere sul serio. SIGReg, la regolarizzazione che forza le rappresentazioni a distribuirsi come una gaussiana ad alta dimensionalità, si comporta male quando la complessità intrinseca dell’ambiente è bassa. Se il mondo da rappresentare ha pochissime dimensioni effettive, forzare il modello a occupare uno spazio latente ricco è controproducente. Il modello “sparge” la propria rappresentazione su dimensioni che non gli servono, perdendo focalizzazione.
È un risultato che fa pensare. Suggerisce una proprietà non triviale della cognizione: per fiorire, ha bisogno di una complessità minima dell’esperienza. Una macchina addestrata in un ambiente troppo povero produce rappresentazioni peggiori di una macchina addestrata in un ambiente ricco. Vale per i bambini cresciuti in deprivazione sensoriale, vale per gli animali in cattività con ambienti monotoni, e a quanto pare vale anche per le reti neurali.
La lezione tocca anche il design dei contesti digitali in cui passiamo le nostre giornate. Se la nostra esperienza quotidiana è troppo curata, troppo ottimizzata, troppo “facile”, potremmo stare costruendo il nostro Two-Room: un ambiente cognitivamente povero che impedisce alle nostre rappresentazioni interne di sviluppare la ricchezza necessaria per affrontare problemi complessi. È un’ipotesi, non una certezza. Ma il dato sperimentale è lì, ed è coerente con tanta letteratura di psicologia dello sviluppo.
Le interfacce che amo non semplificano tutto a oltranza, lasciano sopravvivere una giusta dose di attrito, di imprevedibilità, di scoperta. Il difficile in sé non ha valore, però senza un minimo di complessità da affrontare l’intelligenza, biologica o artificiale, si appiattisce.

Verso uno strato spaziale comune
Le tecnologie raramente arrivano da sole. Arrivano in convergenze. I world model latenti come LeWM, i modelli generativi 3D come Marble di World Labs, l’hardware per realtà mista che si è fatto ragionevolmente buono negli ultimi due anni, l’industria della robotica che torna a investire dopo la traversata del deserto, le auto a guida autonoma che cominciano davvero a funzionare in alcune città americane. Sono tutti vettori che spingono nella stessa direzione: un mondo computazionalmente aumentato in cui l’intelligenza non sta più dietro uno schermo, ma è distribuita nello spazio fisico, negli oggetti, negli ambienti, e talvolta sul nostro corpo come pelle aggiuntiva.
LeWorldModel è uno dei mattoni invisibili di questa transizione. Da solo non vediamo che cosa diventerà. Tra cinque anni guarderemo indietro e diremo: ecco, da lì in poi le macchine hanno cominciato davvero a pensare al mondo, non solo alle parole sul mondo. È il passaggio che separa l’AI che descrive dall’AI che agisce, e nei prossimi due o tre anni vedremo emergere i primi prodotti che lo incorporeranno in modo invisibile.
Per chi costruisce prodotti, oggi, il segnale operativo è abbastanza chiaro. Continuare a presidiare i LLM dove servono (testo, codice, ragionamento simbolico), iniziare a presidiare i world model dove cominciano a contare (manipolazione fisica, navigazione, simulazione, predizione di sistemi complessi). Non sono mondi separati, si parleranno tra loro, ma sono filoni tecnici con strumenti, talenti e logiche diverse. Chi crede che basti aspettare un GPT-6 generalista per coprire entrambi, probabilmente sbaglia. Le architetture che funzionano per il testo non funzionano per la fisica intuitiva, e viceversa. Sono due forme di intelligenza che devono convivere.
Per chi si occupa di cultura e di formazione, c’è un tema parallelo. Stiamo entrando in un’epoca in cui le macchine sviluppano forme rudimentali di “buon senso fisico”, e la nostra responsabilità verso le tecnologie cambia di nuovo. Non bastano più gli strumenti per usare il digitale, servono strumenti per comprenderne le rappresentazioni interne, le scelte percettive, le gerarchie ontologiche implicite. Sapere che un’AI distingue la sostanza dall’apparenza diventa informazione utile per chiunque la userà, così come riconoscere il suo bisogno di varietà per sviluppare rappresentazioni ricche cambia il modo in cui chi le addestra prepara i dataset. Una proprietà come lo straightening temporale delle traiettorie interne diventa pertinente anche per chi integra questi modelli in sistemi più grandi.
Sono cose che oggi sembrano da specialisti, e che tra dieci anni faranno parte della cultura generale, come oggi è cultura generale capire grossomodo come funziona un motore di ricerca, anche senza saperne scrivere uno. Le persone che cominciano a capirle adesso saranno quelle che parteciperanno alla conversazione su come queste macchine entreranno nelle vite di tutti, e probabilmente faranno scelte diverse da chi resta nella sola dimensione linguistica.
C’è una scena che immagino spesso, ed è quella di un robot domestico che, dopo aver ricevuto l’istruzione di prendere un bicchiere fragile dal tavolo, si ferma un attimo, “vede” mentalmente cosa succederebbe se lo afferrasse con troppa forza, e modula la presa di conseguenza. Quel “vede mentalmente” non è una metafora, è esattamente la pianificazione in spazio latente che LeWorldModel comincia a fare oggi nei suoi ambienti semplificati. Quando quella stessa capacità sarà nei robot di casa, nei droni di consegna, nei sistemi di assistenza alla guida, avremo macchine che hanno ricominciato a vivere il mondo, dopo decenni in cui l’avevano solo letto.
Il preprint che ho davanti, in fondo, è un pezzo piccolo di una storia molto più grande. La storia di come, in questo decennio, l’intelligenza è tornata a incarnarsi.