L’Europa e l’AI di frontiera che non controlla
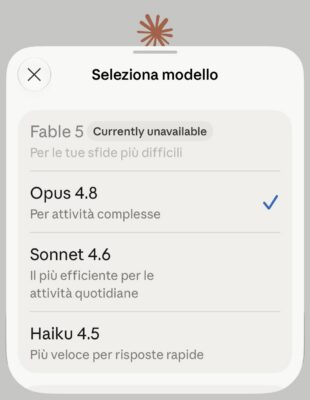
Il 7 luglio la Commissione europea ha presentato un Action Plan su cybersicurezza e intelligenza artificiale. A firmarlo è Henna Virkkunen, che nella nuova Commissione porta una delega dal nome esplicito, sovranità tecnologica, sicurezza e democrazia, e che ha messo in fila un ragionamento semplice, l’AI sta cambiando il significato stesso della sicurezza informatica e l’Europa deve tenere il passo alle vulnerabilità che le nuove tecnologie si portano dietro. Nelle settimane precedenti, a Bruxelles, si leggeva un fatto molto preciso: un modello di frontiera, il Mythos di Anthropic, aveva mostrato di saper individuare vulnerabilità nascoste nel software, e un governo straniero aveva deciso di limitarne l’accesso a chi non è cittadino americano.
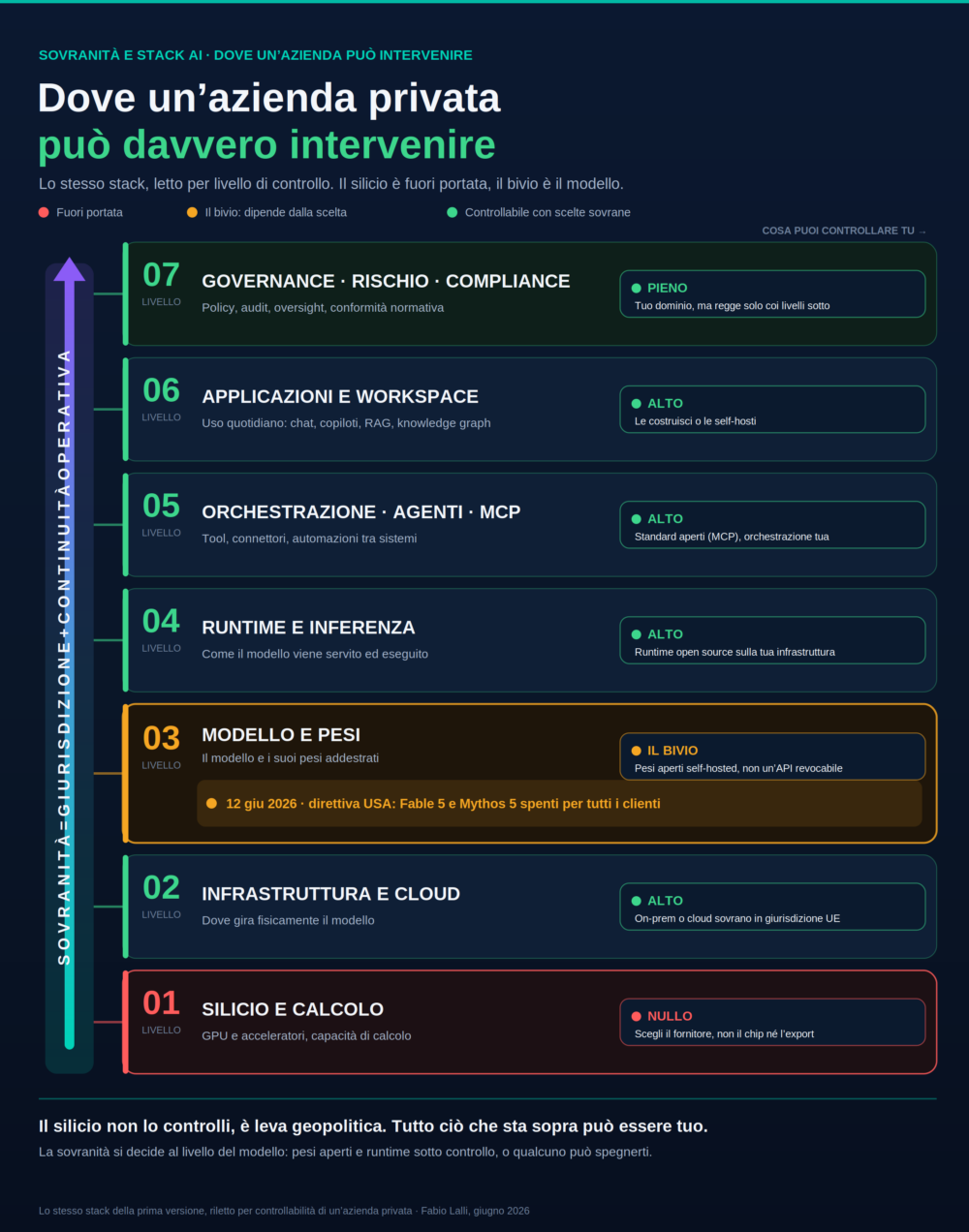
Per anni l’Europa ha scritto regole per un’intelligenza artificiale che non costruisce. Questo piano è il primo documento che lo dice ad alta voce, con parole sue: le capacità di frontiera nascono per lo più fuori dai confini dell’Unione, e la loro disponibilità dipende da processi decisi altrove, spesso poco trasparenti. La cybersicurezza, letta così, non è un problema di adempimento, è un problema di sovranità digitale.
Una capacità di valutazione da costruire
La prima mossa concreta è una capacità europea di valutazione dei modelli, che la Commissione vuole creare nel 2027. Servirà a esaminare i modelli di frontiera prima che arrivino sul mercato, anche dal lato della sicurezza informatica, a sostegno del lavoro dell’AI Office, con criteri pubblici per i valutatori indipendenti che vorranno candidarsi.
Sotto l’annuncio c’è un’ammissione. Oggi l’Europa non riesce a valutare da sola i modelli che pretende di regolare. L’AI Act le ha dato il diritto di chiedere che quei modelli vengano esaminati, questo piano riconosce che le manca il muscolo per farlo in proprio.
Il primo pezzo di quel muscolo arriva prima. ENISA, l’agenzia dell’Unione per la cybersicurezza, e il Centro comune di ricerca costruiranno entro fine 2026 una piattaforma europea sicura per mettere alla prova i modelli in ambienti simulati, portando competenza sull’uso sicuro dell’AI agli operatori dei settori critici, dalla finanza alla sanità, dall’energia ai trasporti fino alla pubblica amministrazione.
Quando a decidere l’accesso è un altro
Qui il piano tocca il nervo scoperto. Le capacità di frontiera, scrive la Commissione, si sviluppano quasi tutte fuori dall’Unione, e chi le vuole usare dipende da processi decisi altrove. Conoscerle e potervi accedere non riguarda soltanto la resilienza informatica, riguarda la sovranità tecnologica di un continente.
L’episodio Mythos serve da promemoria. Un modello capace di trovare falle nascoste diventa un’arma se finisce nelle mani sbagliate, uno strumento di difesa se resta in quelle giuste, però la mano che decide chi può usarlo, in quel caso, stava a Washington e non a Bruxelles. È l’idea del permesso revocabile portata su scala geopolitica: quando il permesso di usare una capacità può essere ritirato da qualcun altro, dall’esterno, la tua sovranità sui processi che quella capacità protegge è presa in prestito.
Somiglia alla competenza presa in prestito di cui scrivevo a proposito del nostro rapporto quotidiano con questi modelli, solo che qui il prestito non tocca una singola persona che smette di saper fare una cosa, tocca la capacità di un’intera economia di difendere le proprie infrastrutture.
Dal codice condiviso alla vulnerabilità che resta scoperta
Il secondo pilastro guarda dentro le organizzazioni. Il piano non chiede di aspettare, chiede di usare da subito le capacità di AI già disponibili, compresi i modelli aperti, per trovare e correggere le vulnerabilità più in fretta di prima, e per reagire quando un attacco è già in corso. Da qui a fine 2026 ENISA pubblicherà linee guida e buone pratiche, e aprirà un progetto pilota sulla resilienza del software libero critico, pensato per accelerare la correzione delle falle con l’aiuto dell’AI.
Il codice aperto, in questo disegno, pesa più di una bandiera ideologica. Resta la sola capacità che un’organizzazione può ispezionare riga per riga e far girare sulle proprie macchine, senza chiedere permesso a nessuno e senza che nessuno la spenga da lontano. La stessa falla che un modello di frontiera straniero potrebbe scovare al posto tuo, oggi, un modello aperto che controlli tu può aiutarti a chiuderla domani.
La difesa prima della norma
C’è un contrasto che vale la pena guardare in faccia. Nelle stesse settimane in cui prepara questo piano, l’Europa rallenta il suo stesso codice: il 29 giugno il Consiglio ha dato il via libera definitivo alla semplificazione dell’AI Act, che sposta in avanti gli obblighi sui sistemi ad alto rischio, al dicembre 2027 per quelli autonomi e all’agosto 2028 per quelli dentro i prodotti.
Frenare la regola e costruire la difesa, allo stesso tempo, sembra una contraddizione e invece è una sola mossa. Il baricentro si sposta da ciò che vietiamo prima a ciò che sappiamo fare adesso, dalla conformità alla capacità. È l’ansia da competitività dei rapporti Draghi e Letta tradotta in atti di governo, e cambia il modo in cui un CIO dovrebbe leggere la politica europea sull’AI.
La lettura solo per adempimento non basta più. Ciò che pesa davvero, sui tavoli dove si decide, è lo stesso metro che vale con gli agenti: la reversibilità, cioè il controllo su runtime, contesto e permessi e la rapidità con cui puoi fermare un processo e riportarlo indietro senza danni.
Sovranità digitale, da iniziare adesso
Il piano, in filigrana, detta anche cosa fare senza aspettare né l’agenzia del 2027 né la sfida europea di fine anno. C’è l’igiene di base da rafforzare e la sicurezza da mettere fin dentro la progettazione, come le regole sulla cybersicurezza già chiedono. Conviene poi iniziare a usare i modelli disponibili, anche quelli aperti, per scovare e chiudere le vulnerabilità e per rispondere quando un attacco è già partito. Merita attenzione, da qui a fine anno, la piattaforma di ENISA per la sperimentazione dei modelli, con le linee guida che arriveranno tra il terzo e il quarto trimestre.
E la dipendenza da un singolo modello di frontiera controllato da un altro Stato va trattata per quello che è, un’esposizione nella catena di fornitura che una decisione presa altrove può accendere o spegnere da un giorno all’altro.
L’occasione, per chi in Europa costruisce sicurezza e AI nello stesso posto, prende una forma concreta. Bruxelles lancerà entro fine 2026 una sfida europea per le soluzioni di cybersicurezza basate sull’AI, e sta studiando con la Banca europea per gli investimenti uno strumento pubblico che finanzi i progetti strategici, la frontiera dell’AI compresa. Attorno a una capacità sovrana, che si possa ispezionare e valutare in casa, si sta formando un mercato.
Il piano costruisce la capacità di valutare i modelli e gli strumenti per difendere le reti, e sono due cose che all’Europa mancano da tempo. Resta però, sui tavoli dove lavoro, una domanda a cui non ho ancora una risposta netta: si può davvero essere sovrani su una capacità che non hai costruito e che non riesci a vedere fino in fondo? Finché la risposta non è chiara, la sovranità digitale somiglia più a un cantiere aperto che a un traguardo raggiunto.
Il documento è l’Action Plan on Cybersecurity and Artificial Intelligence presentato dalla Commissione europea il 7 luglio 2026, con il comunicato integrale della Commissione. La struttura in tre pilastri e le scadenze operative sono ricostruite dal servizio di Agence Europe. Il via libera definitivo alla semplificazione dell’AI Act è del Consiglio dell’UE, 29 giugno 2026.